Pipeline 执行引擎
一句话定义
Pipeline 执行引擎是 Doris 自 3.0 起替代火山模型的并行执行模型,参考 Hyper 论文中 Pipeline 的实现方式,通过将查询拆分为可并行执行的 Pipeline 与 PipelineTask,充分释放多核 CPU 算力,并限制查询线程数,从而解决线程膨胀问题。
概览 Checklist
阅读本文前,建议先了解以下要点:
- Pipeline 执行引擎在 Doris 3.0 之后已彻底替换原有的火山模型。
- 基于 Pipeline 模型,Doris 实现了 Query、DDL、DML 语句的并行处理。
- 详细设计、实现与效果可参阅以下两篇 DSIP:
物理计划
要理解 Pipeline 执行模型,需要先了解物理查询计划中两个核心概念:PlanFragment 和 PlanNode。下面通过一条示例 SQL 进行说明:
SELECT k1, SUM(v1) FROM A,B WHERE A.k2 = B.k2 GROUP BY k1 ORDER BY SUM(v1);
逻辑计划
FE 首先会把这条 SQL 翻译成如下逻辑计划,计划中每个节点就是一个 PlanNode。每种 Node 的具体含义可参考查看物理计划的介绍。
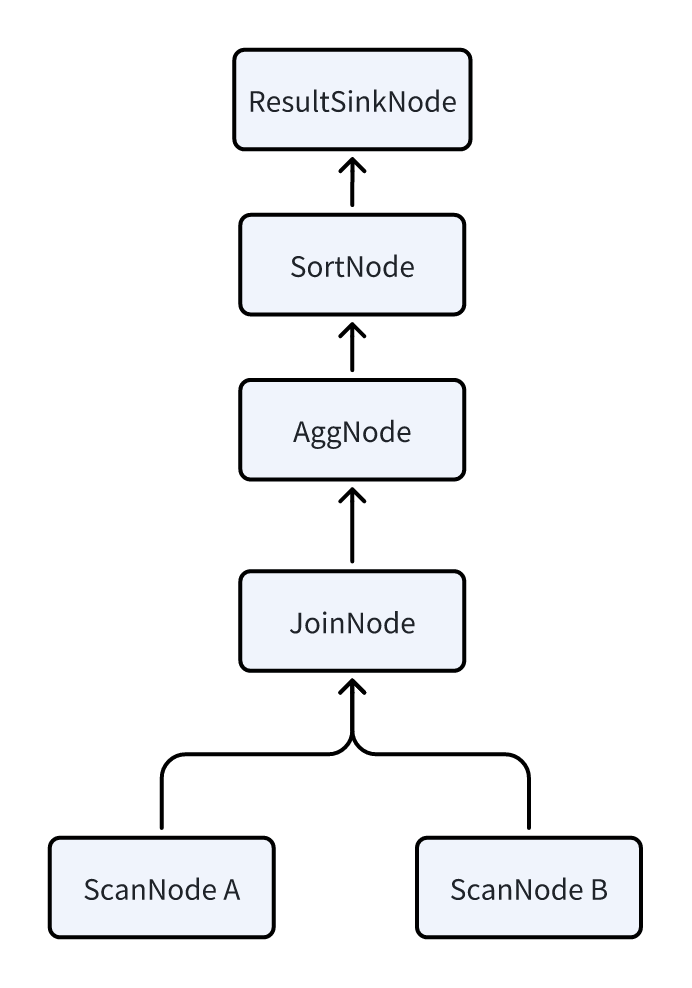
物理计划
由于 Doris 是一个 MPP 架构,每个查询都会尽可能让所有 BE 都参与并行执行,以降低查询延时。因此还需要将逻辑计划拆分为物理计划:
- 在逻辑计划中插入
DataSink和ExchangeNode,通过这两个 Node 完成数据在多个 BE 之间的 Shuffle。 - 拆分完成后,每个 PlanFragment 包含一部分 PlanNode,可作为独立任务发送给 BE。
- 每个 BE 完成 PlanFragment 内 PlanNode 的计算后,再通过
DataSink和ExchangeNode把数据 shuffle 到其他 BE 上继续计算。
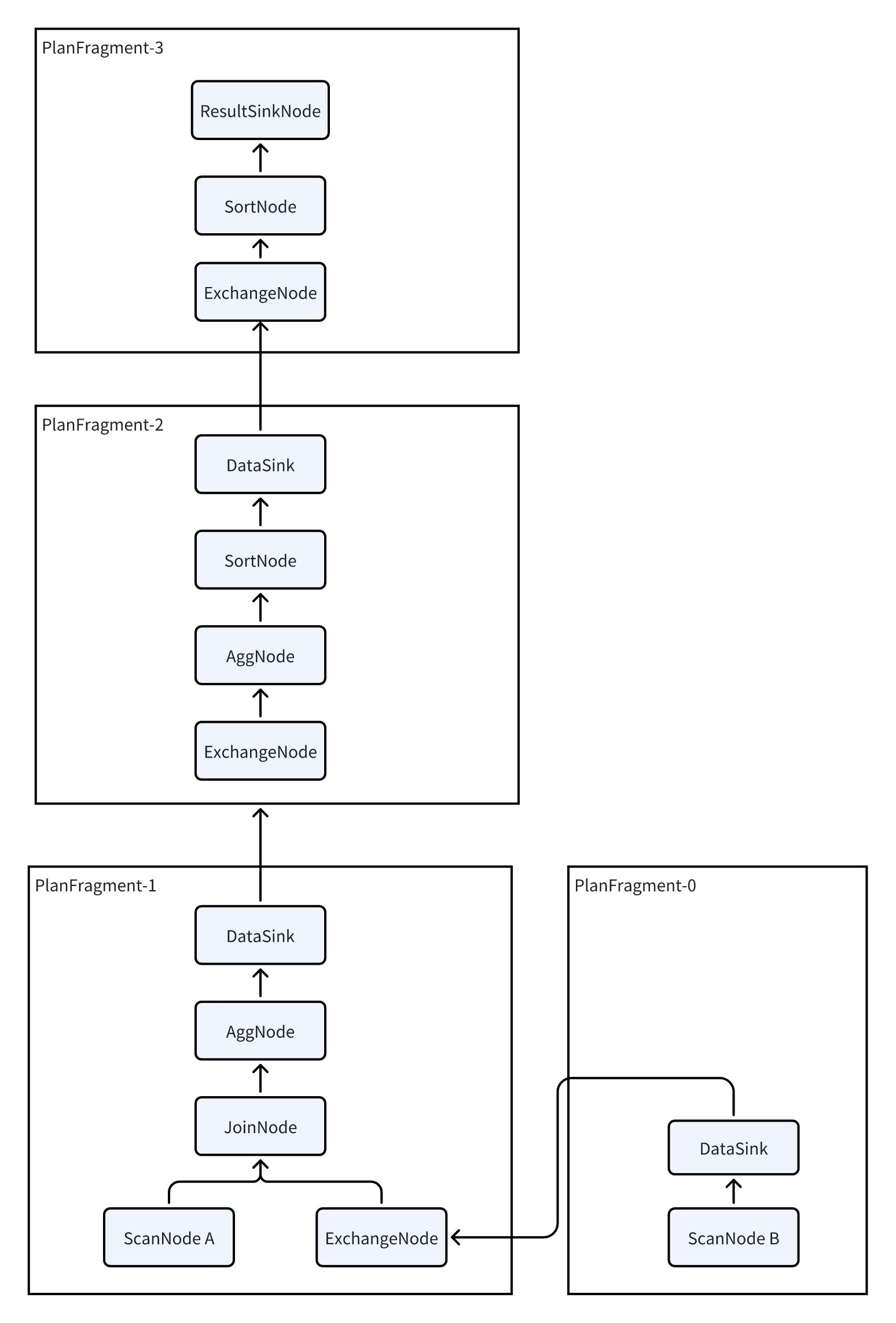
三层规划结构
Doris 的规划分为以下 3 层:
| 层级 | 名称 | 说明 |
|---|---|---|
| 1 | PLAN(执行计划) | 一个 SQL 会被执行规划器翻译成一个执行计划,之后由执行引擎执行。 |
| 2 | FRAGMENT(执行片段) | Doris 是分布式执行引擎,一个完整的执行计划会被切分为多个单机执行片段。一个 FRAGMENT 代表一个完整的单机执行片段,多个 FRAGMENT 组合在一起构成一个完整的 PLAN。 |
| 3 | PLAN NODE(算子) | 执行计划的最小单位。一个 FRAGMENT 由多个算子构成,每个算子负责一个实际的执行逻辑,比如聚合、连接等。 |
Pipeline 执行模型
PlanFragment 是 FE 发往 BE 执行任务的最小单位。BE 可能会收到同一个 Query 的多个不同 PlanFragment,每个 PlanFragment 会被单独处理。
收到 PlanFragment 后,BE 的处理流程如下:
- 把 PlanFragment 拆分为多个 Pipeline。
- 启动多个 PipelineTask 实现并行执行。
- 提升查询效率。
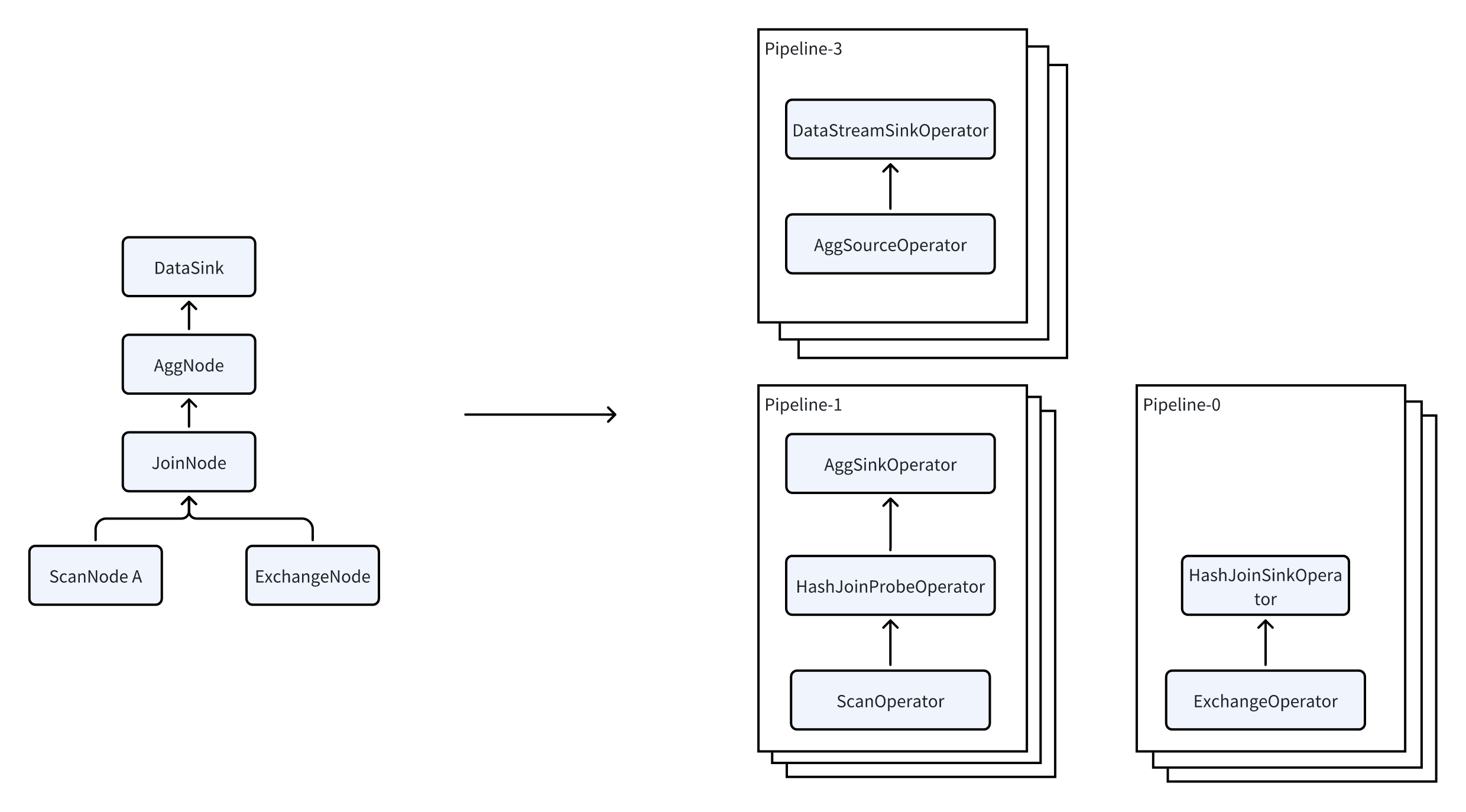
Pipeline
一个 Pipeline 由如下部分组成:
- 一个 SourceOperator:代表从外部读取数据,可以是一张表(OlapTable),也可以是一个 Buffer(Exchange)。
- 中间的多个其他 Operator。
- 一个 SinkOperator:表示数据的输出,可以是通过网络 shuffle 到别的节点(如
DataStreamSinkOperator),也可以是输出到 HashTable(如 Agg 算子的JoinBuildHashTable等)。
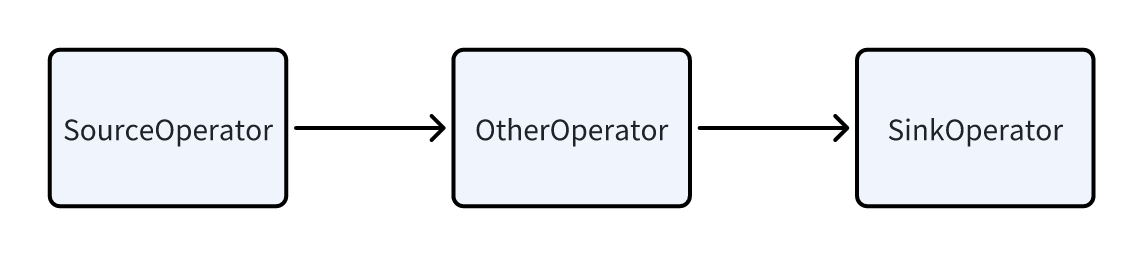
Pipeline 之间的依赖关系(Dependency)
多个 Pipeline 之间存在依赖关系。以 JoinNode 为例,它实际被拆分到 2 个 Pipeline 中:
- Pipeline-0:读取 Exchange 的数据,用于构建 HashTable。
- Pipeline-1:从表中读取数据,用于进行 Probe。
这两个 Pipeline 的关系如下:
- Pipeline-1 的执行依赖 Pipeline-0 完成。
- 这种依赖关系称为 Dependency。
- 当 Pipeline-0 运行完毕后,会调用 Dependency 的
set_ready方法通知 Pipeline-1 可执行。
PipelineTask
Pipeline 实际上仍是一个逻辑概念,并不是可执行实体。要真正执行,需要把 Pipeline 实例化为多个 PipelineTask:
- 将需要读取的数据分配给不同的 PipelineTask,最终实现并行处理。
- 同一个 Pipeline 的多个 PipelineTask 之间的 Operator 完全相同,区别在于 Operator 的状态不一样(例如读取的数据不同、构建出的 HashTable 不同等),这些不同的状态称为 LocalState。
- 每个 PipelineTask 最终都会被提交到一个线程池中作为独立任务执行。
在 Dependency 这种触发机制下,可以更好地利用多核 CPU,实现充分并行。
Operator
在大多数情况下,Pipeline 中的每个 Operator 对应一个 PlanNode,但有一些特殊算子例外:
| 原 PlanNode | 拆分后的 Operator |
|---|---|
| JoinNode | JoinBuildOperator + JoinProbeOperator |
| AggNode | AggSinkOperator + AggSourceOperator |
| SortNode | SortSinkOperator + SortSourceOperator |
拆分原理:对于一些 breaking 算子(指需要把所有数据都收集齐之后才能运算的算子),把灌入数据的部分拆分为 Sink,把从这个算子里获取数据的部分称为 Source。
Scan 并行化
扫描数据是非常重的 IO 操作,需要从本地磁盘读取大量数据(在数据湖场景下需从 HDFS 或 S3 中读取,延时更长)。为优化扫描效率,Doris 在 ScanOperator 中引入了并行扫描技术:
- ScanOperator 会动态生成多个 Scanner。
- 每个 Scanner 扫描 100 万 ~ 200 万行左右的数据。
- 每个 Scanner 在做数据扫描时完成相应的数据解压、过滤等计算任务。
- Scanner 把数据发送给一个 DataQueue,供 ScanOperator 读取。
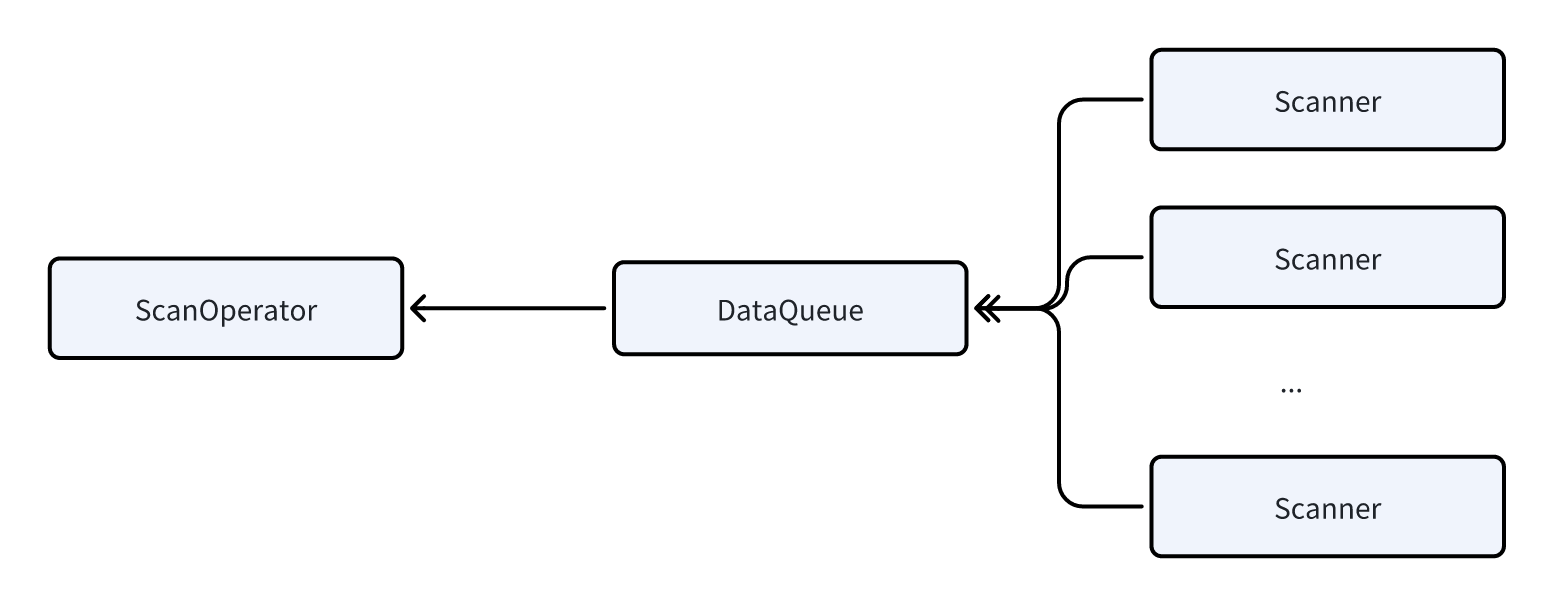
收益:通过并行扫描技术,可以有效避免由于分桶不合理或数据倾斜导致的某些 ScanOperator 执行时间过长,从而拖慢整个查询延时的问题。
Local Shuffle
在 Pipeline 执行模型中,Local Exchange 作为 Pipeline Breaker 出现,是一种在本地将数据重新分发至各个执行任务的技术。
它的作用如下:
- 把上游 Pipeline 输出的全部数据以某种方式(HASH / Round Robin)均匀分发到下游 Pipeline 的全部 Task。
- 解决执行过程中的数据倾斜问题。
- 使执行模型不再受数据存储以及 plan 的限制。
工作示例
下面以前述例子中的 Pipeline-1 为例,说明 Local Exchange 如何避免数据倾斜。
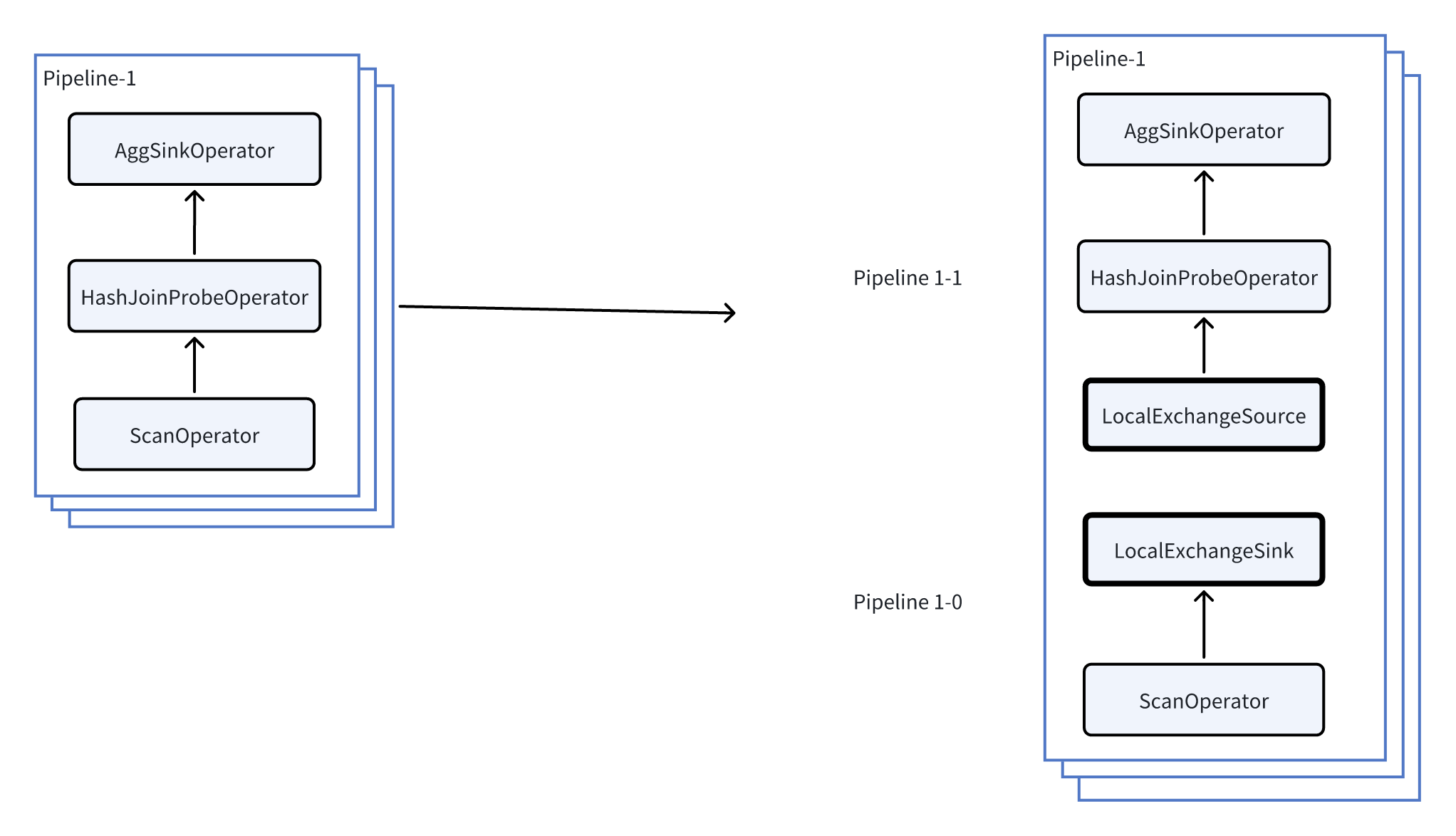
如上图所示,通过在 Pipeline 1 中插入 Local Exchange,把 Pipeline 1 进一步拆分为:
- Pipeline 1-0
- Pipeline 1-1
假设当前并发等于 3(每个 Pipeline 有 3 个 task),每个 task 读取存储层的一个 bucket,3 个 bucket 中数据行数分别是 1、1、7。则插入 Local Exchange 前后的执行变化如下:
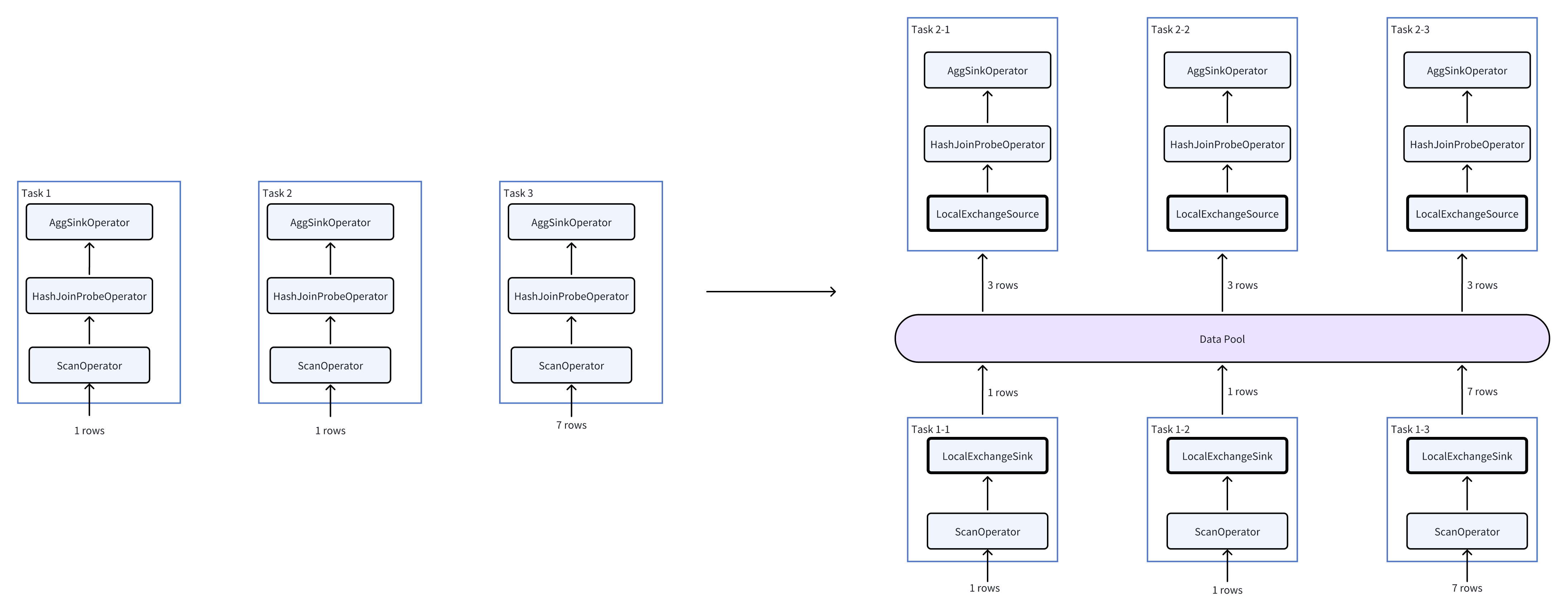
从图右可以看出,HashJoin 和 Agg 算子需要处理的数据量从 (1, 1, 7) 变成了 (3, 3, 3),从而避免了数据倾斜。
规划规则
在 Doris 中,Local Exchange 根据一系列规则决定是否被规划。例如:当查询中存在耗时较大的 Join、聚合、窗口函数等算子时,会使用 Local Exchange,尽可能避免数据倾斜。