NGram BloomFilter 索引
NGram BloomFilter 索引是一种跳数索引(Skip Index),专门用于加速字符串列的 LIKE '%pattern%' 模糊查询。它在 BloomFilter 索引的基础上引入 N-Gram 分词,将文本拆分为多个相邻字符组成的词组后再写入 BloomFilter,从而支持模糊匹配的快速过滤。
核心收益: 在合适的场景下,相比无索引的全量扫描,NGram BloomFilter 索引可带来数倍至十倍的查询加速(参见使用示例中的 8 倍加速案例)。
索引原理
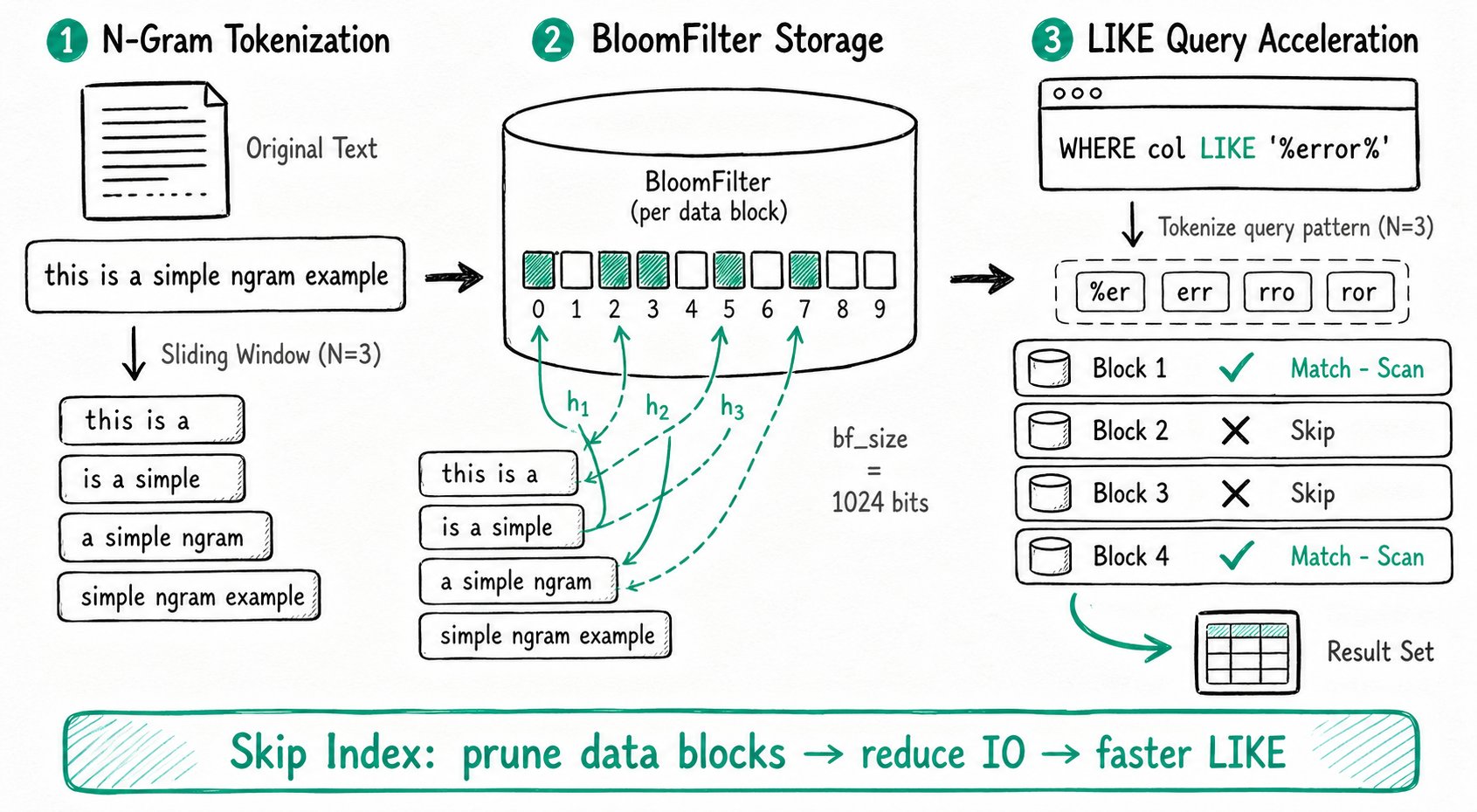
N-Gram 分词将一句话或一段文字拆分为多个相邻字符构成的词组。例如对字符串 'This is a simple ngram example' 在 N = 3 时进行分词,会得到以下 4 个词:
'This is a''is a simple''a simple ngram''simple ngram example'
NGram BloomFilter 索引与普通 BloomFilter 索引的关键区别:
| 对比项 | BloomFilter 索引 | NGram BloomFilter 索引 |
|---|---|---|
| 写入内容 | 列的原始值 | 对原始文本进行 N-Gram 分词后的每个词组 |
| 加速查询类型 | 等值查询(=、IN) | LIKE '%pattern%' 模糊查询 |
| 适用列类型 | 多种数据类型 | 仅字符串列 |
查询加速过程:
- 对
LIKE '%pattern%'中的pattern进行 N-Gram 分词。 - 逐个判断分词后的词组是否在 BloomFilter 中。
- 若某个词组不在 BloomFilter 中,对应数据块必然不满足 LIKE 条件,可以跳过该数据块。
- 通过跳过不命中的数据块减少 IO,从而加速查询。
使用场景
NGram BloomFilter 索引适用于以下场景:
- 字符串列上的
LIKE '%pattern%'模糊查询加速。 LIKEpattern 中的连续字符个数 大于等于 索引定义的gram_size。
- 仅支持字符串列,仅能加速
LIKE查询。 - NGram BloomFilter 索引与普通 BloomFilter 索引为互斥关系,同一列只能选择其中一种。
- 索引效果分析方式与 BloomFilter 索引一致。
管理索引
创建索引
建表时创建
在建表语句中 COLUMN 定义之后添加索引定义:
INDEX `idx_column_name` (`column_name`) USING NGRAM_BF
PROPERTIES("gram_size"="3", "bf_size"="1024")
COMMENT 'username ngram_bf index'
语法说明
| 参数 | 是否必填 | 说明 |
|---|---|---|
idx_column_name (column_name) | 必填 | column_name 为建索引的列名,必须在前面已定义;idx_column_name 为索引名,需在表内唯一 |
USING NGRAM_BF | 必填 | 指定索引类型为 NGram BloomFilter 索引 |
PROPERTIES | 可选 | 指定 NGram BloomFilter 索引的额外属性,详见下表 |
COMMENT | 可选 | 指定索引注释 |
建议索引名以 idx_ 作为前缀,例如 idx_review_body。
PROPERTIES 参数
| 属性 | 说明 |
|---|---|
gram_size | N-Gram 中的 N,指定每 N 个连续字符为一个词组。例如 'This is a simple ngram example' 在 N = 3 时分为 4 个词组。建议取 LIKE 查询字符串的最小长度,但不建议低于 2。 |
bf_size | BloomFilter 的大小,单位为 Bit。决定每个数据块对应的索引大小,值越大占用存储空间越多,同时 Hash 碰撞概率越低。 |
推荐配置: 一般建议先设置 "gram_size"="3"、"bf_size"="1024",再根据 Query Profile 进行调优。
查看索引
-- 方式 1:在表的 schema 中 INDEX 部分,USING NGRAM_BF 标识为 NGram BloomFilter 索引
SHOW CREATE TABLE table_name;
-- 方式 2:IndexType 为 NGRAM_BF 标识为 NGram BloomFilter 索引
SHOW INDEX FROM idx_name;
删除索引
ALTER TABLE table_ngrambf DROP INDEX idx_ngrambf;
修改索引
NGram BloomFilter 索引可通过以下两种方式新增到已有表中:
-- 方式 1:使用 CREATE INDEX
CREATE INDEX idx_column_name2(column_name2) ON table_ngrambf
USING NGRAM_BF
PROPERTIES("gram_size"="3", "bf_size"="1024")
COMMENT 'username ngram_bf index';
-- 方式 2:使用 ALTER TABLE ADD INDEX
ALTER TABLE table_ngrambf
ADD INDEX idx_column_name2(column_name2) USING NGRAM_BF
PROPERTIES("gram_size"="3", "bf_size"="1024")
COMMENT 'username ngram_bf index';
使用索引
启用函数下推
使用 NGram BloomFilter 索引前需启用函数下推(enable_function_pushdown 默认为 false):
SET enable_function_pushdown = true;
触发索引加速
NGram BloomFilter 索引会自动用于加速 LIKE 查询,例如:
SELECT count() FROM table1 WHERE message LIKE '%error%';
索引效果分析
可通过 Query Profile 中的以下指标分析 BloomFilter 索引(包括 NGram BloomFilter)的加速效果:
| 指标 | 含义 |
|---|---|
RowsBloomFilterFiltered | BloomFilter 索引过滤掉的行数,可与其他 Rows 指标对比分析过滤效果 |
BlockConditionsFilteredBloomFilterTime | BloomFilter 索引消耗的时间 |
使用示例
以亚马逊产品的用户评论数据集 amazon_reviews 为例,演示 NGram BloomFilter 索引的使用方式与加速效果。
第 1 步:建表
CREATE TABLE `amazon_reviews` (
`review_date` int(11) NULL,
`marketplace` varchar(20) NULL,
`customer_id` bigint(20) NULL,
`review_id` varchar(40) NULL,
`product_id` varchar(10) NULL,
`product_parent` bigint(20) NULL,
`product_title` varchar(500) NULL,
`product_category` varchar(50) NULL,
`star_rating` smallint(6) NULL,
`helpful_votes` int(11) NULL,
`total_votes` int(11) NULL,
`vine` boolean NULL,
`verified_purchase` boolean NULL,
`review_headline` varchar(500) NULL,
`review_body` string NULL
) ENGINE=OLAP
DUPLICATE KEY(`review_date`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`review_date`) BUCKETS 16
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"compression" = "ZSTD"
);
第 2 步:导入数据
1. 下载数据集
使用 wget 或其他工具从下面的地址下载数据集:
https://datasets-documentation.s3.eu-west-3.amazonaws.com/amazon_reviews/amazon_reviews_2010.snappy.parquet
https://datasets-documentation.s3.eu-west-3.amazonaws.com/amazon_reviews/amazon_reviews_2011.snappy.parquet
https://datasets-documentation.s3.eu-west-3.amazonaws.com/amazon_reviews/amazon_reviews_2012.snappy.parquet
https://datasets-documentation.s3.eu-west-3.amazonaws.com/amazon_reviews/amazon_reviews_2013.snappy.parquet
https://datasets-documentation.s3.eu-west-3.amazonaws.com/amazon_reviews/amazon_reviews_2014.snappy.parquet
https://datasets-documentation.s3.eu-west-3.amazonaws.com/amazon_reviews/amazon_reviews_2015.snappy.parquet
2. 通过 Stream Load 导入
curl --location-trusted -u root: -T amazon_reviews_2010.snappy.parquet -H "format:parquet" http://127.0.0.1:8030/api/${DB}/amazon_reviews/_stream_load
curl --location-trusted -u root: -T amazon_reviews_2011.snappy.parquet -H "format:parquet" http://127.0.0.1:8030/api/${DB}/amazon_reviews/_stream_load
curl --location-trusted -u root: -T amazon_reviews_2012.snappy.parquet -H "format:parquet" http://127.0.0.1:8030/api/${DB}/amazon_reviews/_stream_load
curl --location-trusted -u root: -T amazon_reviews_2013.snappy.parquet -H "format:parquet" http://127.0.0.1:8030/api/${DB}/amazon_reviews/_stream_load
curl --location-trusted -u root: -T amazon_reviews_2014.snappy.parquet -H "format:parquet" http://127.0.0.1:8030/api/${DB}/amazon_reviews/_stream_load
curl --location-trusted -u root: -T amazon_reviews_2015.snappy.parquet -H "format:parquet" http://127.0.0.1:8030/api/${DB}/amazon_reviews/_stream_load
上述文件可能超过 10 GB,需要调整 be.conf 中的 streaming_load_max_mb 防止超过 Stream Load 文件上传大小限制。可通过以下命令动态调整(每台 BE 都需执行):
curl -X POST http://{be_ip}:{be_http_port}/api/update_config?streaming_load_max_mb=32768
3. 验证数据导入
通过 SQL 运行 count() 确认导入数据成功:
mysql> SELECT COUNT() FROM amazon_reviews;
+-----------+
| count(*) |
+-----------+
| 135589433 |
+-----------+
第 3 步:性能对比
场景 1:无索引查询(耗时 7.60s)
SELECT
product_id,
any_value(product_title),
AVG(star_rating) AS rating,
COUNT() AS count
FROM
amazon_reviews
WHERE
review_body LIKE '%is super awesome%'
GROUP BY
product_id
ORDER BY
count DESC,
rating DESC,
product_id
LIMIT 5;
查询结果:
+------------+------------------------------------------+--------------------+-------+
| product_id | any_value(product_title) | rating | count |
+------------+------------------------------------------+--------------------+-------+
| B00992CF6W | Minecraft | 4.8235294117647056 | 17 |
| B009UX2YAC | Subway Surfers | 4.7777777777777777 | 9 |
| B00DJFIMW6 | Minion Rush: Despicable Me Official Game | 4.875 | 8 |
| B0086700CM | Temple Run | 5 | 6 |
| B00KWVZ750 | Angry Birds Epic RPG | 5 | 6 |
+------------+------------------------------------------+--------------------+-------+
5 rows in set (7.60 sec)
场景 2:添加 NGram BloomFilter 索引后(耗时 0.93s)
添加索引:
ALTER TABLE amazon_reviews
ADD INDEX review_body_ngram_idx(review_body) USING NGRAM_BF
PROPERTIES("gram_size"="10", "bf_size"="10240");
再次执行相同查询:
+------------+------------------------------------------+--------------------+-------+
| product_id | any_value(product_title) | rating | count |
+------------+------------------------------------------+--------------------+-------+
| B00992CF6W | Minecraft | 4.8235294117647056 | 17 |
| B009UX2YAC | Subway Surfers | 4.7777777777777777 | 9 |
| B00DJFIMW6 | Minion Rush: Despicable Me Official Game | 4.875 | 8 |
| B0086700CM | Temple Run | 5 | 6 |
| B00KWVZ750 | Angry Birds Epic RPG | 5 | 6 |
+------------+------------------------------------------+--------------------+-------+
5 rows in set (0.93 sec)
性能对比:
| 场景 | 耗时 | 性能提升 |
|---|---|---|
| 无索引 | 7.60 s | 基准 |
| 添加 NGram BloomFilter 索引 | 0.93 s | 约 8 倍 |