前缀索引与排序键
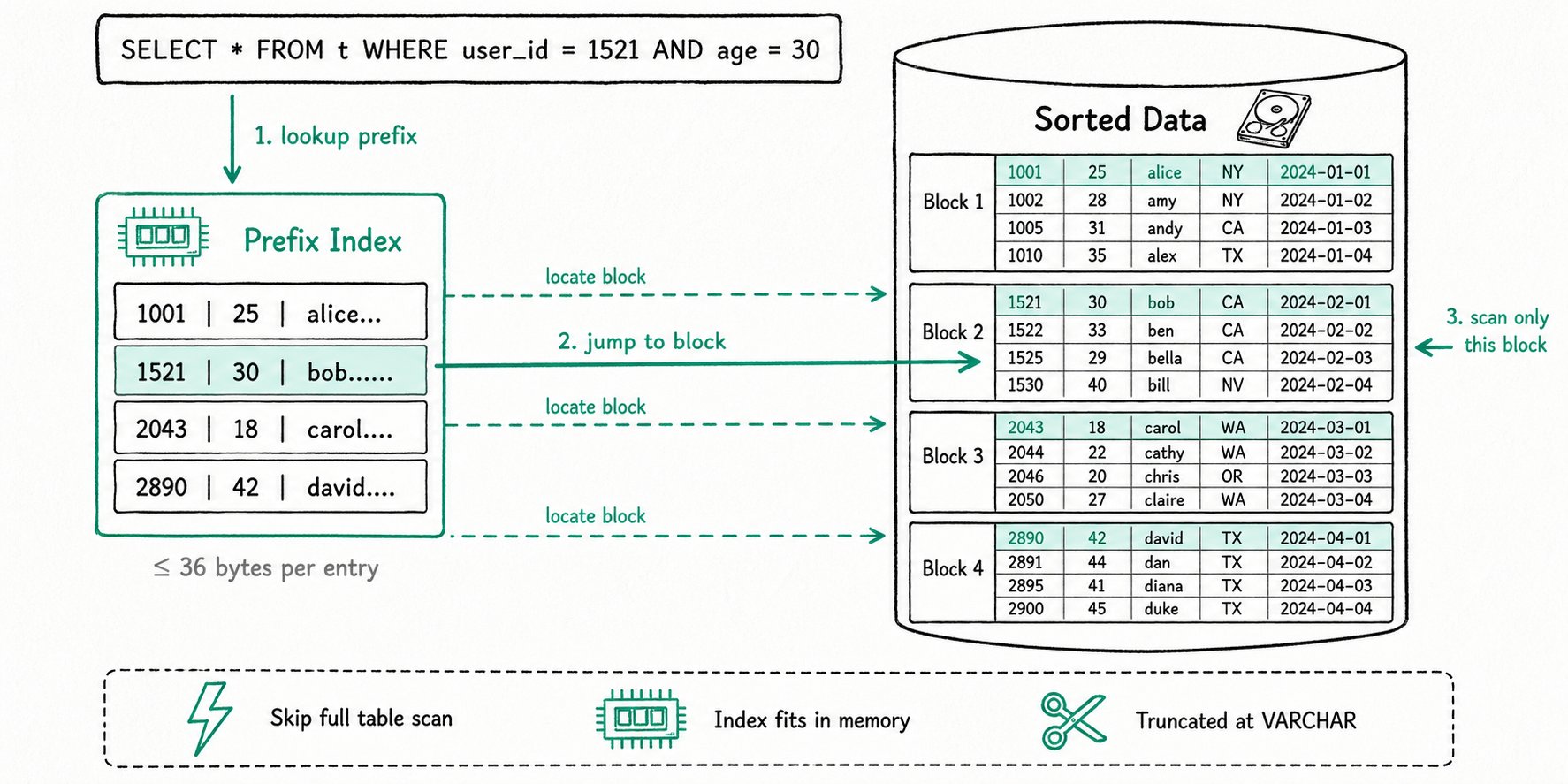
前缀索引(Prefix Index)是 Apache Doris 内置且自动维护的稀疏索引,依据排序键的前 36 字节快速定位数据块,无需用户手动创建。在表结构设计阶段合理选择排序键,即可显著加速 WHERE 条件中的等值查询和范围查询。
工作原理
排序键(Sort Key)
Apache Doris 的数据存储在类似 SSTable(Sorted String Table)的有序结构中,可以按指定的一列或多列排序存储。这些用于排序的列称为排序键(Sort Key)。
不同数据模型的排序键定义来源不同:
| 数据模型 | 排序键来源 |
|---|---|
| Aggregate | 建表语句中的 Aggregate Key |
| Unique | 建表语句中的 Unique Key |
| Duplicate | 建表语句中的 Duplicate Key |
借助排序键,查询时只要 WHERE 条件命中排序列,Doris 就能快速跳转到对应数据范围,避免全表扫描,从而降低搜索复杂度、加速查询。
前缀索引(Prefix Index)
在排序键的基础上,Apache Doris 进一步引入了前缀索引:
- 表中每隔若干行的数据组成一个逻辑数据块(Data Block)。
- 每个数据块在前缀索引表中只保留一条索引项,索引项内容为该块第一行排序列拼接而成的前缀,长度不超过 36 字节。
- 由于前缀索引体积小,可以全量缓存在内存中,能够快速定位到目标数据块的起始行号,大幅提升查询效率。
36 字节截断规则
前缀索引取一行排序列的前 36 字节作为索引内容,但遇到 VARCHAR 类型时会直接截断:
- 排序列拼接到
VARCHAR列时,无论是否凑满 36 字节,都会在该列结束处截断。 - 若第一列就是
VARCHAR,即使长度不足 36 字节,也会截断,后续列不再加入前缀索引。
适用场景
前缀索引主要服务于以下查询场景:
- 等值查询:
col = value、col IN (...) - 范围查询:
col > value、BETWEEN ... AND ...等
只要 WHERE 条件命中排序键的前缀(即从最左列开始的若干列),即可被前缀索引加速。
表结构设计建议
由于一个表的排序键定义是唯一的,因此一个表只能拥有一组前缀索引。建表时排序键的选择直接决定了前缀索引的加速效果,可参考以下原则:
- 优先选择最常出现在 WHERE 过滤条件中的列作为 Key 列。
- 将查询频率更高的列放在前面,因为前缀索引仅对从最左列开始连续命中的条件有效。
- 谨慎将
VARCHAR列放在排序键前部,避免触发截断导致后续列无法进入前缀索引。
若高频查询条件无法通过调整排序键来命中前缀索引,可参考下文 无法命中前缀索引时的替代方案。
使用示例
示例 1:前缀索引未发生截断
排序键如下,前缀索引为 user_id (8 Bytes) + age (4 Bytes) + message (前 20 Bytes),合计 32 Bytes:
| ColumnName | Type |
|---|---|
| user_id | BIGINT |
| age | INT |
| message | VARCHAR(100) |
| max_dwell_time | DATETIME |
| min_dwell_time | DATETIME |
示例 2:首列即为 VARCHAR 触发截断
排序键如下,前缀索引仅为 user_name (20 Bytes)。即便未达到 36 字节,因首列为 VARCHAR 而直接截断,后续列不会进入前缀索引:
| ColumnName | Type |
|---|---|
| user_name | VARCHAR(20) |
| age | INT |
| message | VARCHAR(100) |
| max_dwell_time | DATETIME |
| min_dwell_time | DATETIME |
示例 3:查询命中 vs 未命中前缀索引
基于示例 1 的表结构:
-
命中前缀索引(条件覆盖排序键最左侧的两列,效率高):
SELECT * FROM table WHERE user_id = 1829239 AND age = 20; -
未命中前缀索引(条件跳过了
user_id,无法使用前缀定位):SELECT * FROM table WHERE age = 20;
因此,建表时正确选择列顺序,能够极大提高查询效率。
验证索引效果
前缀索引在能加速时自动生效,没有特殊语法。可通过 Query Profile 中的以下指标验证加速效果:
| 指标 | 含义 |
|---|---|
RowsKeyRangeFiltered | 通过前缀索引过滤掉的行数。可与其他 Rows* 指标对比,评估索引过滤效果。 |
无法命中前缀索引时的替代方案
当高频查询条件无法命中前缀索引时(例如某些常用过滤列并非排序键前缀),可考虑以下两种方案:
常见问题(FAQ)
Q1:前缀索引需要手动创建吗?
不需要。建表时 Doris 会自动取排序键的前 36 字节作为前缀索引,没有专门的 DDL 语法。
Q2:一张表可以有多组前缀索引吗?
不可以。由于排序键唯一,一张表只能有一组前缀索引。如需多组,建议借助倒排索引或物化视图实现。
Q3:为什么我的前缀索引比预期短很多?
最常见原因是排序键中靠前的位置出现了 VARCHAR 列,触发了截断规则。建议把定长类型(如 BIGINT、INT、DATETIME)放在排序键前部。
Q4:前缀索引能加速 LIKE 或文本检索吗?
不能。LIKE 模糊匹配和全文检索建议分别使用 NGram BloomFilter 索引 与 倒排索引。