大规模性能实测
本文给出 Doris ANN Index 在中大规模与亿级数据集上的导入与查询性能实测结果,帮助用户评估在不同数据规模下的查询表现,并理解如何从单机部署平滑扩展到分布式部署。
快速导航
阅读本文,可以回答以下问题:
- 千万级向量数据,单台 BE 能否承载在线检索?预期 QPS 与延迟是多少?
- 亿级向量数据,单机内存不足时,如何通过多 BE 部署继续提供向量查询能力?
- 不同向量维度(768/1536)和距离度量(
inner_product/l2_distance)的性能差异如何? - 如何复现这些测试结果?
测试环境与数据集
部署形态
| 部署模式 | BE 节点数 | 单节点规格 | 适用数据规模 |
|---|---|---|---|
| 单机 | 1 | 16C64GB | 千万级 |
| 分布式 | 3 | 16C64GB | 亿级 |
FE 与 BE 分离部署,所有测试均使用 VectorDBBench 工具。
数据集概览
| 数据集 | 数据量 | 向量维度 | 距离度量 | 部署形态 |
|---|---|---|---|---|
| Performance768D10M | 10M | 768 | inner_product | 单机 |
| Performance1536D5M | 5M | 1536 | inner_product | 单机 |
| Performance768D100M | 100M | 768 | l2_distance | 分布式 |
单机实测(16C64GB)
单机结果给出了中大规模数据集上的 ANN 查询性能基线。
导入性能
两个数据集的导入指标如下:
| 项目 | Performance768D10M | Performance1536D5M |
|---|---|---|
| 向量维度 | 768 | 1536 |
metric_type | inner_product | inner_product |
| 数据量 | 10M 行 | 5M 行 |
| 导入 batch 参数 | NUM_PER_BATCH=500000--stream-load-rows-per-batch 500000 | NUM_PER_BATCH=250000--stream-load-rows-per-batch 250000 |
| 导入耗时 | 76m41s | 41m |
show data all | 56.498 GB(25.354 GB + 31.145 GB) | 55.223 GB(25.346 GB + 29.878 GB) |
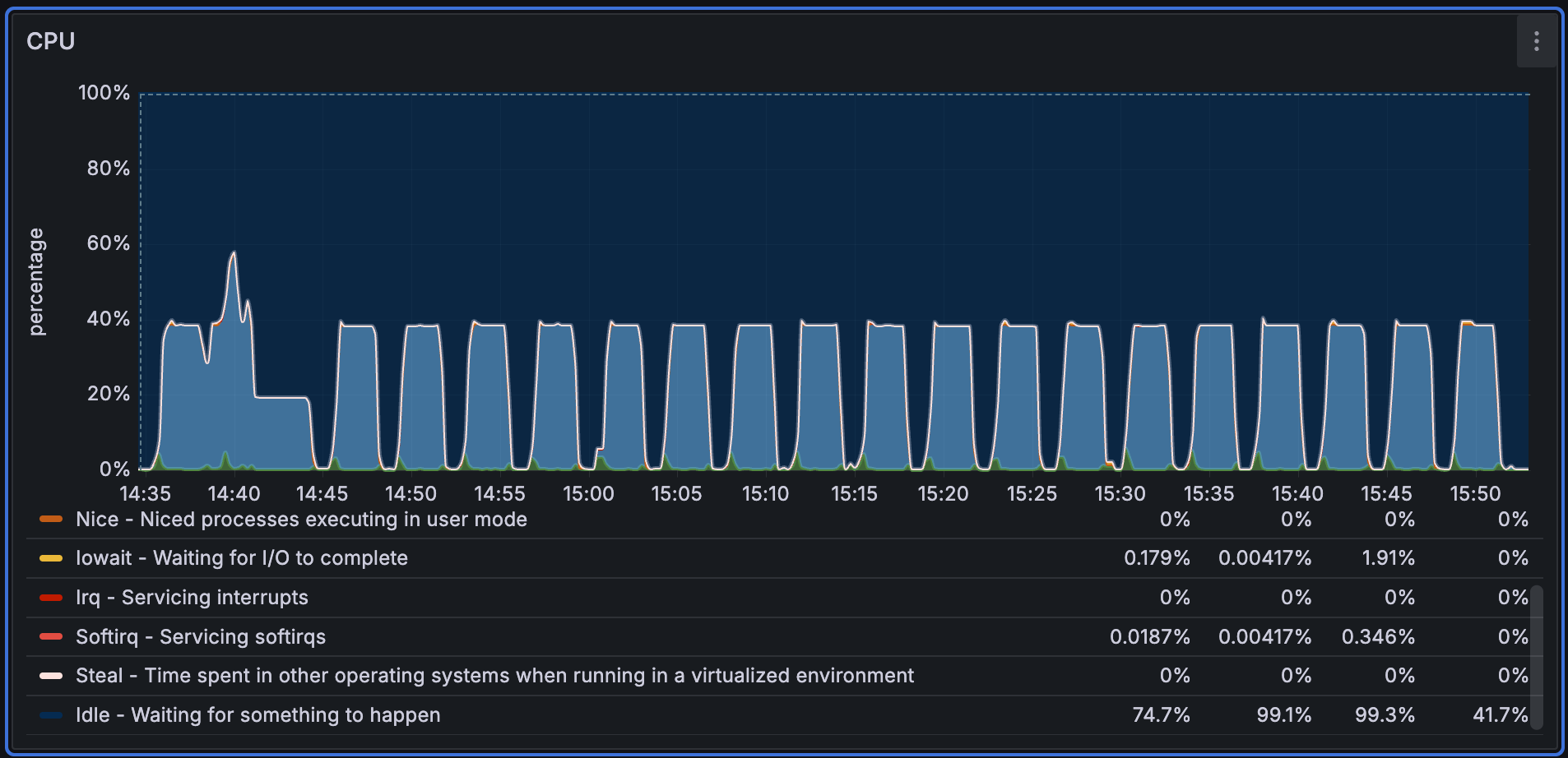
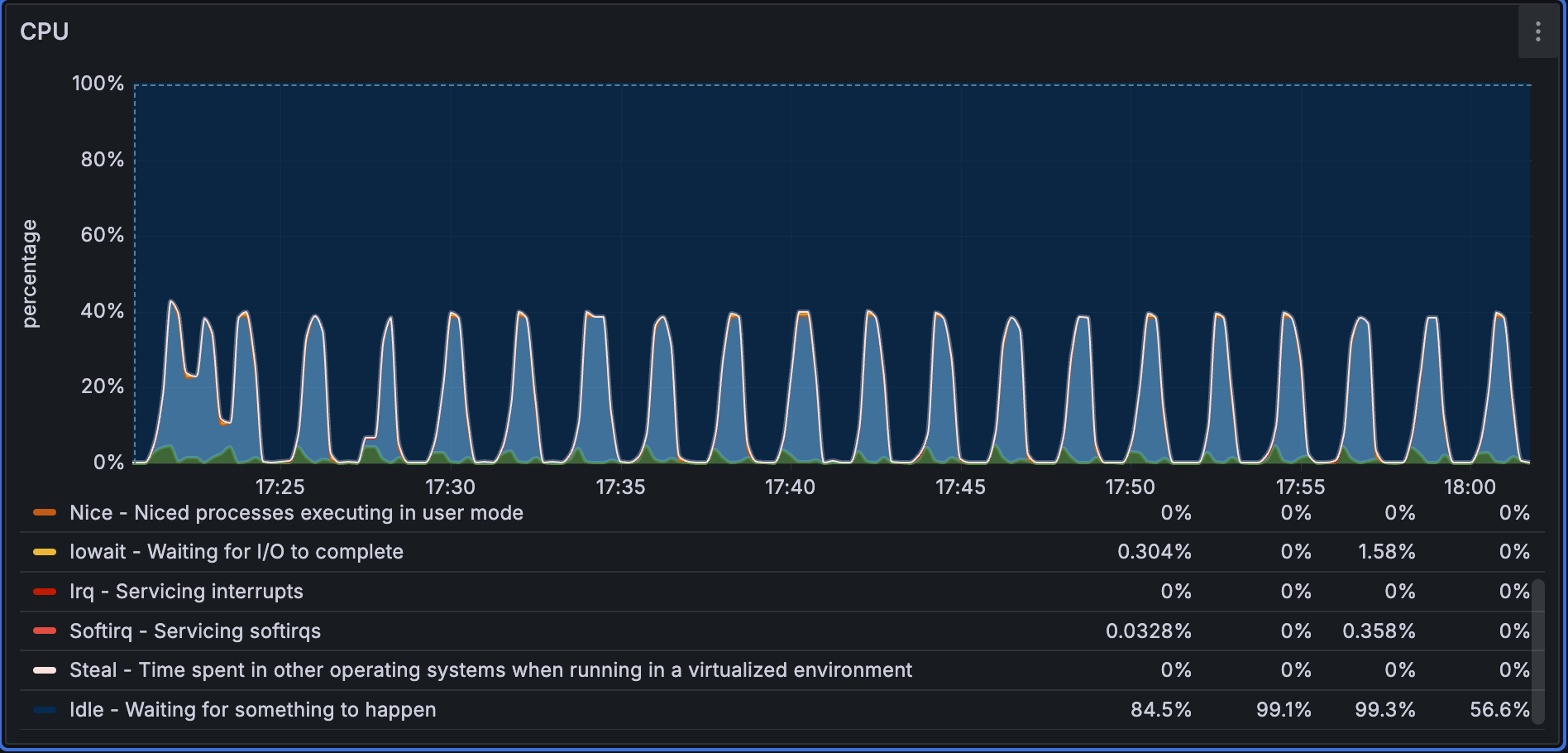
CPU 使用情况:
-
Performance768D10M 导入期间 CPU 使用率整体较为平稳。
-
Performance1536D5M 数据量较小、batch size 也更小,因此导入阶段 CPU 使用率波动更为频繁。
查询性能
在保持较高召回率的前提下,单机部署能够达到数百 QPS,并维持较低查询延迟。
汇总指标
| 数据集 | BestQPS | Recall@100 |
|---|---|---|
| Performance768D10M | 481.9356 | 0.9207 |
| Performance1536D5M | 414.7342 | 0.9677 |
Performance768D10M 明细(inner_product,10M 行)
| 并发数 | QPS | P95 延迟 | P99 延迟 | 平均延迟 |
|---|---|---|---|---|
| 10 | 116.2000 | 0.0932 | 0.0933 | 0.0861 |
| 40 | 455.9485 | 0.1102 | 0.1225 | 0.0877 |
| 80 | 481.9356 | 0.2331 | 0.2674 | 0.1658 |
Performance1536D5M 明细(inner_product,5M 行)
| 并发数 | QPS | P95 延迟 | P99 延迟 | 平均延迟 |
|---|---|---|---|---|
| 10 | 144.3221 | 0.0764 | 0.0800 | 0.0693 |
| 40 | 401.9732 | 0.1271 | 0.1404 | 0.0994 |
| 80 | 414.7342 | 0.2772 | 0.3222 | 0.1925 |
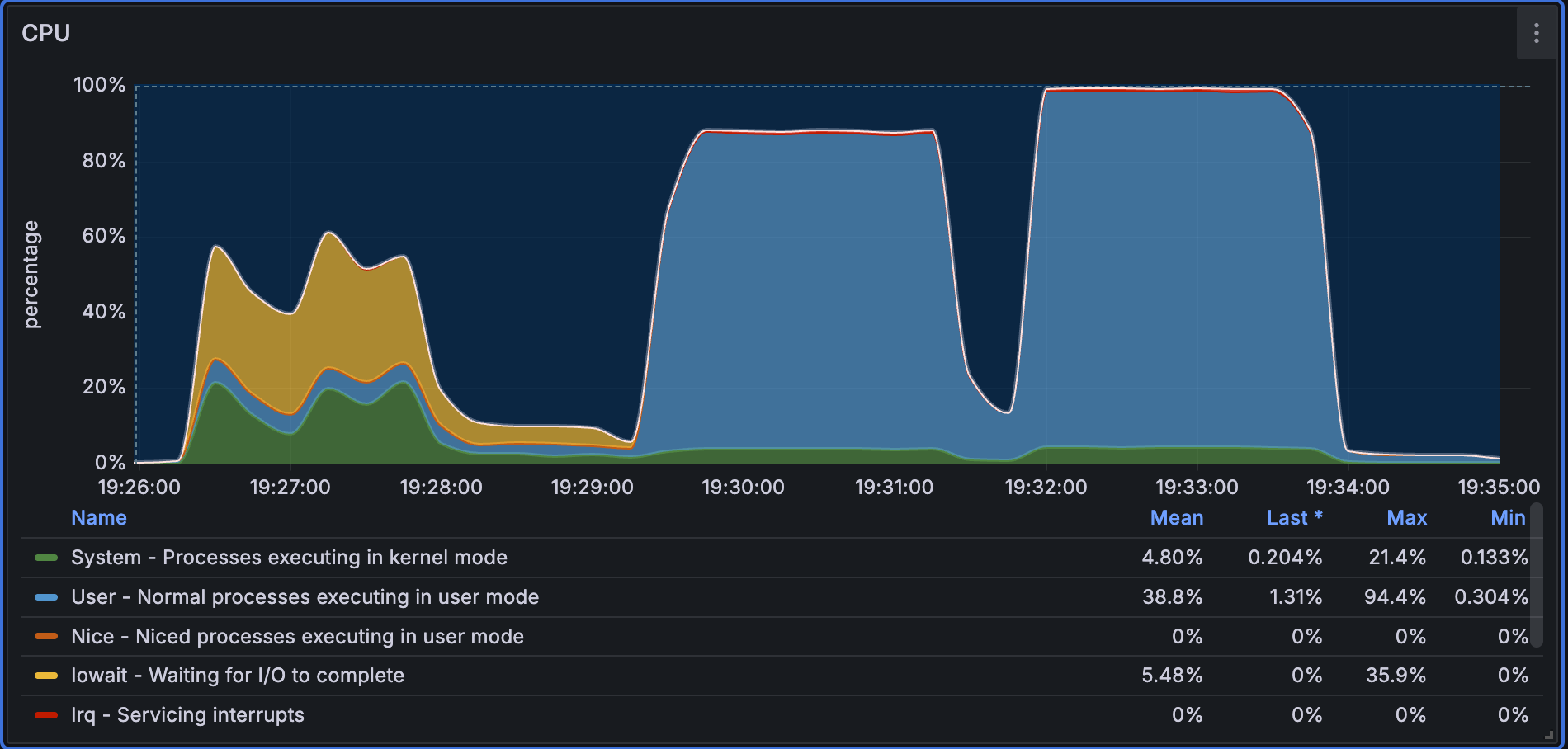
CPU 监控
冷查询阶段需要将索引加载到内存,CPU 利用率相对较低,系统主要在等待 IO;进入热查询阶段后,CPU 利用率明显提升并接近 100%。
分布式实测(3 × 16C64GB)
当数据规模超出单台 16C64GB 的合理内存承载范围时,可通过多 BE 部署横向扩展。本节使用 Performance768D100M 数据集(100M 行、768 维),展示 100M 规模下 Doris 仍可提供在线向量查询能力。
本测试与单机小规模测试不构成一一对应的绝对数值比较,更适合用于观察规模扩展表现。
导入与索引构建
由于单机内存上限为 64GB,本测试采用向量量化压缩以降低内存开销。
| 项目 | 数值 |
|---|---|
| 数据集 | Performance768D100M |
| 数据量 | 100M 行 |
| 向量维度 | 768 |
| batch 参数 | NUM_PER_BATCH=500000--stream-load-rows-per-batch 500000 |
| 索引参数 | "dim"="768", "index_type"="hnsw", "metric_type"="l2_distance", "pq_m"="384", "pq_nbits"="8", "quantizer"="pq" |
| build index 用时 | 4h5min |
show data all | 198.809 GB(137.259 GB + 61.550 GB) |
索引构建后数据分布:
- 共 3 个 bucket
- 每个 bucket 含 34 个 rowset,每个 rowset 约 1.99 GB
- 每个 rowset 含 6 个 segment
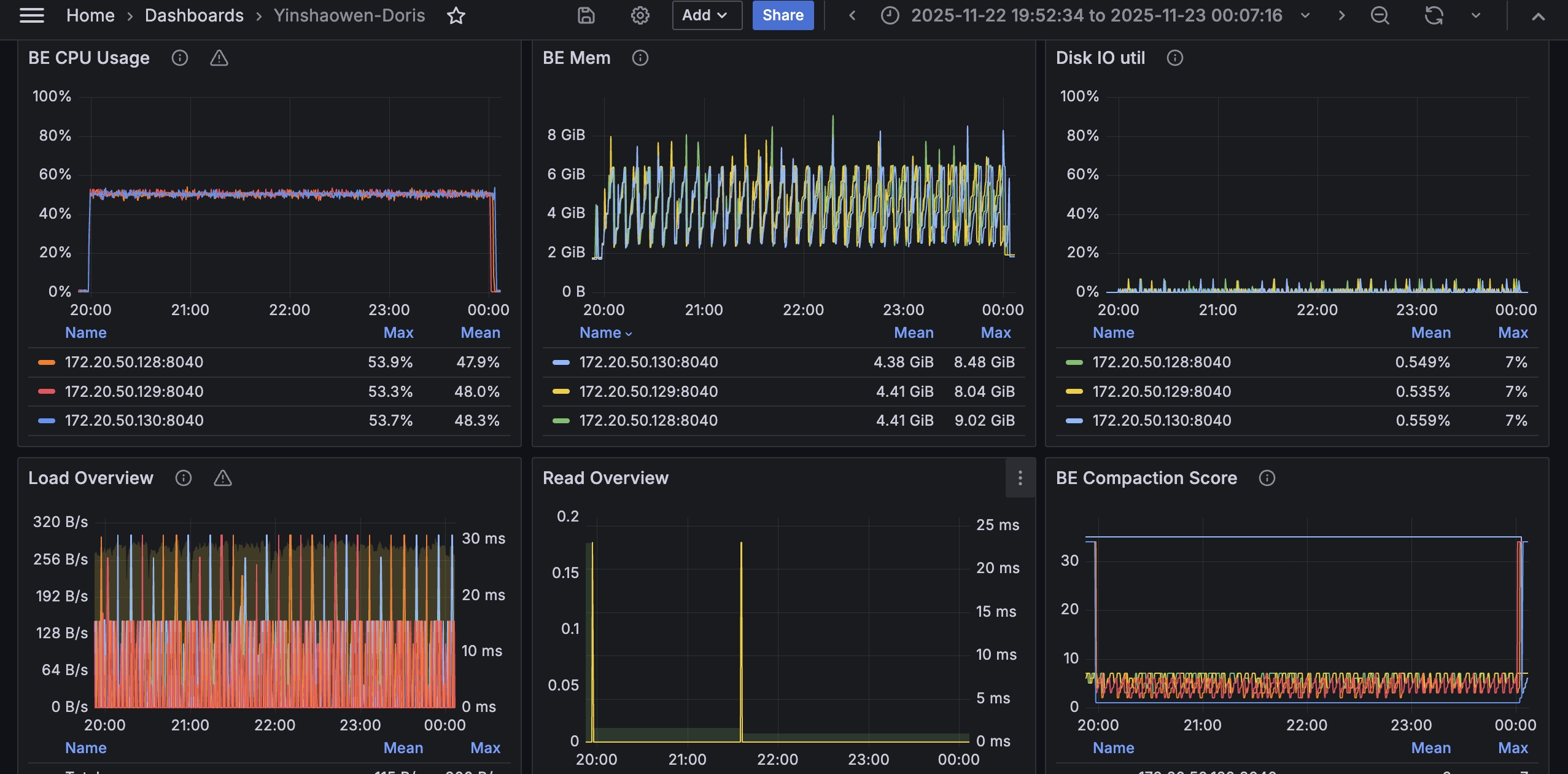
CPU 使用情况: 索引构建期间 CPU 使用率整体稳定在约 50%,未长时间打满 CPU,仍保留了一定资源余量。
查询性能
汇总指标
| 指标 | 数值 |
|---|---|
| BestQPS | 77.6247 |
| Recall@100 | 0.9294 |
明细(l2_distance,100M 行)
| 并发数 | QPS | P95 延迟 | P99 延迟 | 平均延迟 |
|---|---|---|---|---|
| 10 | 46.5836 | 0.2628 | 0.2791 | 0.2145 |
| 20 | 75.3579 | 0.3251 | 0.3541 | 0.2651 |
| 30 | 77.6247 | 0.5222 | 0.5766 | 0.3860 |
| 40 | 76.6313 | 0.7089 | 0.7854 | 0.5212 |
CPU 监控
查询阶段各节点 CPU 使用率保持在较高水平,说明查询负载较充分地利用了分布式计算资源。
关键结论
- 千万级单机: 在千万级向量数据规模下,Doris 单机部署可提供数百 QPS 的 ANN 查询性能,并保持较高召回率(≥0.92)。
- 亿级分布式: 在 100M 向量数据集上,可通过多 BE 部署 + 向量量化压缩继续提供在线向量查询能力(BestQPS ≈ 77,Recall@100 ≈ 0.93)。
- 横向扩展能力: 当数据规模超过单机内存承载范围时,分布式部署是延续在线检索能力的可行路径。
测试说明
阅读测试结果时请注意以下几点:
- 距离度量不同: 单机测试使用
inner_product,分布式测试使用l2_distance,不建议直接横向对比绝对数值。 - 数据规模与索引参数不同: 各测试组的数据规模与索引参数(如是否启用量化)不一致,结果更适合观察规模扩展表现。
- 冷查询修正: 单机
Performance768D10M在并发 10 下的结果已剔除冷查询影响后进行修正。
复现方式
测试基于 VectorDBBench 工具执行。
单机复现
# Performance768D10M
export NUM_PER_BATCH=500000
vectordbbench doris ... --case-type Performance768D10M --stream-load-rows-per-batch 500000
# Performance1536D5M
export NUM_PER_BATCH=250000
vectordbbench doris ... --case-type Performance1536D5M --stream-load-rows-per-batch 250000
分布式 3BE 复现
export NUM_PER_BATCH=500000
vectordbbench doris ... --case-type Performance768D100M --stream-load-rows-per-batch 500000
FAQ
Q1:单机 16C64GB 最大可承载多少向量?
依赖向量维度、是否启用量化以及索引参数。本文中 768 维 10M 行(约 56 GB)可在 16C64GB 单机稳定运行;若数据规模继续扩大或维度更高,建议启用向量量化或采用多 BE 分布式部署。
Q2:为何分布式测试的 QPS 低于单机?
两组测试的距离度量、数据规模与索引参数均不同(分布式启用了 PQ 量化),因此不能直接横向对比绝对数值。分布式测试的目的是验证大规模数据下的可扩展性,而非追求最大 QPS。
Q3:为什么需要在 100M 数据上启用量化?
单机内存上限为 64GB,100M 768 维向量原始大小已超出内存承载范围。通过 PQ 量化(pq_m=384, pq_nbits=8)可显著降低内存占用,使大规模在线检索成为可能。
Q4:导入耗时是否包含索引构建时间?
单机测试中的"导入耗时"为整体写入时间,索引在写入过程中或后台 compaction 阶段构建。分布式测试中单独列出了 build index 用时,便于评估大规模场景下的索引构建成本。