存储格式 V3
存储格式 V3 是 Segment V2 的继任者。核心变化:列元数据不再打包在 Segment Footer 中,而是存储到文件内的独立区域。这去掉了 V2 在列数达到几百甚至几千时遇到的元数据加载瓶颈。
核心优化点
外部列元数据(External Column Meta)
V2 中,所有列的 ColumnMetaPB 都放在 Segment Footer 里。当表有几百甚至几千列时,Footer 可以膨胀到几 MB。打开一个 Segment 就要加载和反序列化全部元数据,即使查询只需读两列。
V3 将 ColumnMetaPB 从 Footer 移到文件内的独立区域,Footer 只保留轻量指针。
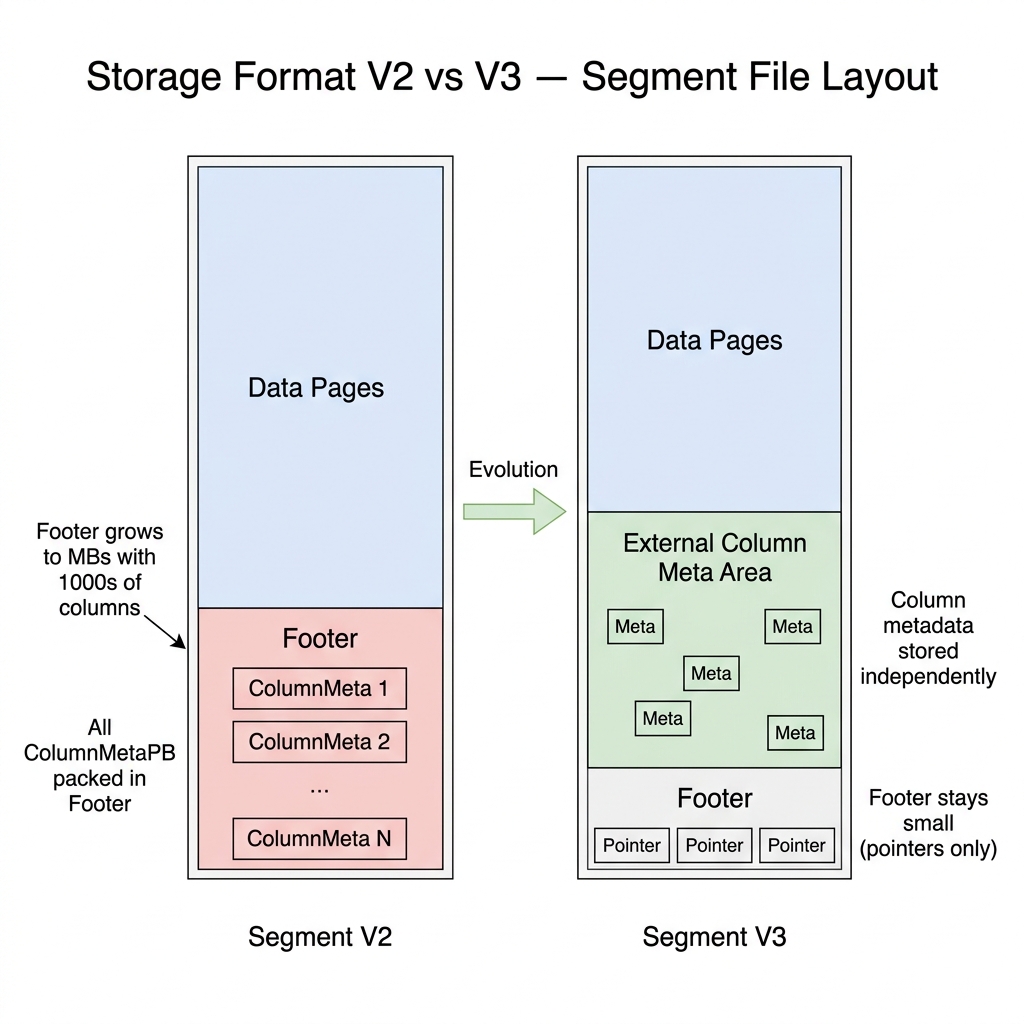
结果:系统先加载一个很小的 Footer,再按需拉取查询所需列的元数据。在对象存储(S3、OSS)上,冷启动延迟大幅降低。
数值类型 Plain 编码
V3 将数值类型(INT、BIGINT 等)的默认编码从 BitShuffle 换成 PLAIN_ENCODING(原始二进制存储)。配合 LZ4 或 ZSTD 压缩,读取速度更快、CPU 开销更低,在大批量扫描时优势明显。
二进制 Plain 编码 V2
V3 为字符串和 JSONB 引入 BINARY_PLAIN_ENCODING_V2。新布局采用 [长度(varuint)][原始数据] 流式结构,去掉了 V2 需要的末尾偏移表,存储更紧凑。
性能数据
以下测试在一张含 7,000 列的宽表上进行,共 10,000 个 Segment。

| 指标 | V2 | V3 | 提升 |
|---|---|---|---|
| Segment 打开时间 | 65 s | 4 s | 快 16 倍 |
| 打开时内存占用 | 60 GB | < 1 GB | 降低 60 倍 |
V2 必须反序列化整个 Footer(包含全部列元数据),即使查询只读几列,也会产生大量无效 I/O 和内存浪费。V3 只读一个精简 Footer,再按需加载列元数据。
什么时候用 V3
- 宽表——列数达到几百或几千。
- 使用
VARIANT的表——子列展开会让实际列数进一步增长。 - 使用对象存储或分层存储,元数据加载延迟敏感。
列数少的普通表,V2 也够用。V3 在列数量大的场景收益最明显。
使用方式
建表时在 PROPERTIES 中指定 storage_format 为 V3:
CREATE TABLE table_v3 (
id BIGINT,
name VARCHAR(128),
attrs VARIANT
)
DISTRIBUTED BY HASH(id) BUCKETS 32
PROPERTIES (
"storage_format" = "V3"
);