Multi-tenancy(Deprecated)
Multi-tenancy(Deprecated)
This function is deprecated. Please see Multi-Tenant.
Background
Doris, as a PB-level online report and multi-dimensional analysis database, provides cloud-based database services through open cloud, and deploys a physical cluster for each client in the cloud. Internally, a physical cluster deploys multiple services, and separately builds clusters for services with high isolation requirements. In view of the above problems:
- Deployment of multiple physical cluster maintenance costs a lot (upgrade, functionality on-line, bug repair).
- A user's query or a bug caused by a query often affects other users.
- In the actual production environment, only one BE process can be deployed on a single machine. Multiple BEs can better solve the problem of fat nodes. And for join, aggregation operations can provide higher concurrency.
Together with the above three points, Doris needs a new multi-tenant scheme, which not only can achieve better resource isolation and fault isolation, but also can reduce the cost of maintenance to meet the needs of common and private clouds.
Design Principles
- Easy to use
- Low Development Cost
- Convenient migration of existing clusters
Noun Interpretation
- FE: Frontend, the module for metadata management or query planning in Doris.
- BE: Backend, the module used to store and query data in Doris.
- Master: A role for FE. A Doris cluster has only one Master and the other FE is Observer or Follower.
- instance: A BE process is an instance in time.
- host: a single physical machine
- Cluster: A cluster consisting of multiple instances.
- Tenant: A cluster belongs to a tenant. Cluster is a one-to-one relationship with tenants.
- database: A user-created database
Main Ideas
- Deploy instances of multiple BEs on a host to isolate resources at the process level.
- Multiple instances form a cluster, and a cluster is assigned to a business-independent tenant.
- FE adds cluster level and is responsible for cluster management.
- CPU, IO, memory and other resources are segregated by cgroup.
Design scheme
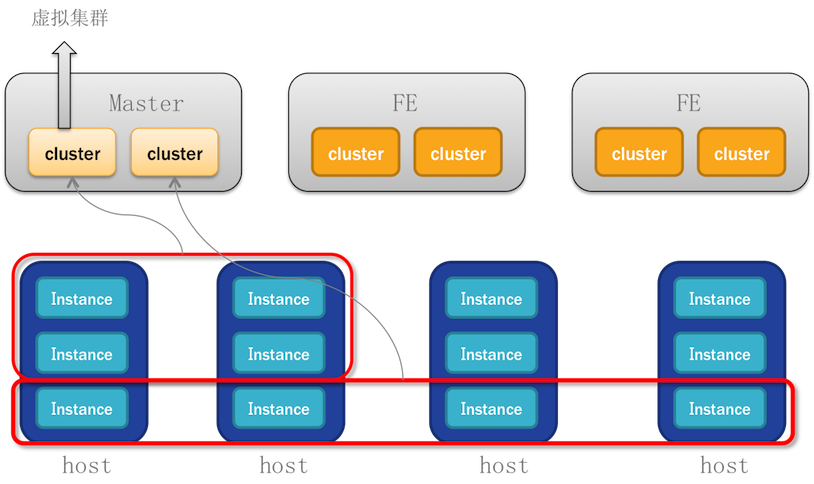
In order to achieve isolation, the concept of virtual cluster is introduced.
- Cluster represents a virtual cluster consisting of instances of multiple BEs. Multiple clusters share FE.
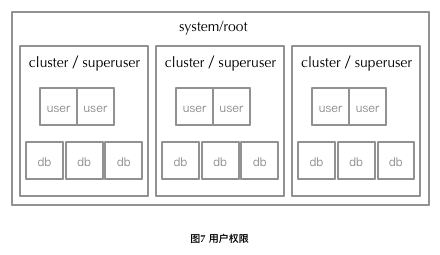
- Multiple instances can be started on a host. When a cluster is created, an arbitrary number of instances are selected to form a cluster.
- While creating a cluster, an account named superuser is created, which belongs to the cluster. Super user can manage clusters, create databases, assign privileges, and so on.
- After Doris starts, the sink creates a default cluster: default_cluster. If the user does not want to use the function of multi-cluster, the default cluster is provided and other operational details of multi-cluster are hidden.
The concrete structure is as follows:
SQL interface
Login
Default cluster login name: user_name@default_cluster or user_name
Custom cluster login name: user_name@cluster_name
mysqlclient -h host -P port -u user_name@cluster_name -p passwordAdd, delete, decommission and cancel BE
ALTER SYSTEM ADD BACKEND "host:port"ALTER SYSTEM DROP BACKEND "host:port"ALTER SYSTEM DECOMMISSION BACKEND "host:port"CANCEL DECOMMISSION BACKEND "host:port"It is strongly recommended to use DECOMMISSION instead of DROP to delete BACKEND. The DECOMMISSION operation will first need to copy data from the offline node to other instances in the cluster. After that, they will be offline.
Create a cluster and specify the password for the superuser account
CREATE CLUSTER cluster_name PROPERTIES ("instance_num" = "10") identified by "password"Enter a cluster
ENTER cluster nameCluster Expansion and Shrinkage
ALTER CLUSTER cluster_name PROPERTIES ("instance_num" = "10")When the number of instances specified is more than the number of existing be in cluster, it is expanded and if less than it is condensed.
Link, migrate DB
LINK DATABASE src_cluster_name.db_name dest_cluster_name.db_nameSoft-chain dB of one cluster to dB of another cluster can be used by users who need temporary access to dB of other clusters but do not need actual data migration.
MIGRATE DATABASE src_cluster_name.db_name dest_cluster_name.db_nameIf you need to migrate dB across clusters, after linking, migrate the actual migration of data.
Migration does not affect the query, import and other operations of the current two dbs. This is an asynchronous operation. You can see the progress of migration through
SHOW MIGRATIONS.Delete clusters
DROP CLUSTER cluster_nameDeleting a cluster requires that all databases in the cluster be deleted manually first.
Others
SHOW CLUSTERSShow clusters that have been created in the system. Only root users have this permission.
SHOW BACKENDSView the BE instance in the cluster.
SHOW MIGRATIONSShow current DB migration tasks. After the migration of DB is completed, you can view the progress of the migration through this command.
Detailed design
Namespace isolation
In order to introduce multi-tenant, the namespaces between clusters in the system need to be isolated.
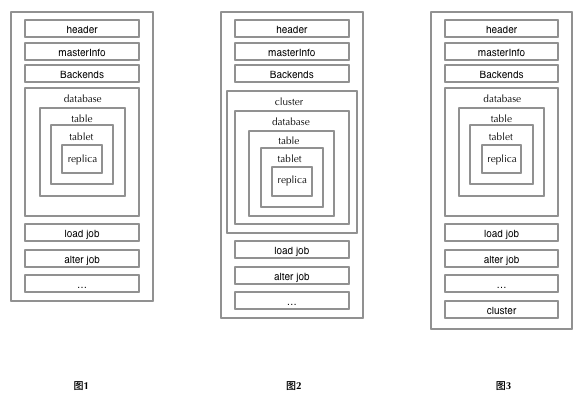
Doris's existing metadata is image + Journal (metadata is designed in related documents). Doris records operations involving metadata as a journal, and then regularly writes images in the form of Fig. 1 and reads them in the order in which they are written when loaded. But this brings a problem that the format that has been written is not easy to modify. For example, the metadata format for recording data distribution is: database + table + tablet + replica nesting. If we want to isolate the namespace between clusters in the past way, we need to add a layer of cluster on the database and the level of internal metadata. Change to cluster + database + table + tablet + replica, as shown in Figure 2. But the problems brought about by adding one layer are as follows:
The change of metadata brought by adding one layer is incompatible. It needs to be written in cluster+db+table+tablet+replica level in the way of Figure 2. This changes the way of metadata organization in the past. The upgrading of the old version will be more troublesome. The ideal way is to write cluster in the order of Figure 3 in the form of existing metadata. Metadata.
All the DB and user used in the code need to add a layer of cluster. There are many workload changes and deep levels. Most of the code acquires db. The existing functions almost need to be changed, and a layer of cluster locks need to be nested on the basis of DB locks.
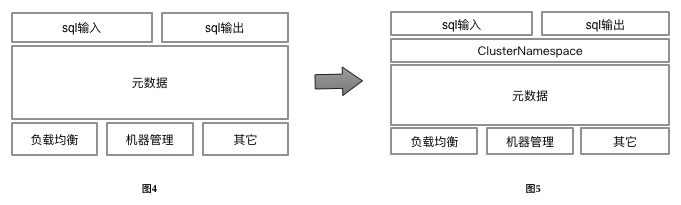
To sum up, we adopt a prefix to DB and user names to isolate the internal problems caused by the conflict of DB and user names between clusters.
As follows, all SQL input involves db name and user name, and all SQL input needs to spell the full name of DB and user according to their cluster.
In this way, the above two problems no longer exist. Metadata is also organized in a relatively simple way. That is to say, use Figure 3 to record db, user and nodes belonging to their own cluster.
BE 节点管理
Each cluster has its own set of instances, which can be viewed through
SHOW BACKENDS. In order to distinguish which cluster the instance belongs to and how it is used, BE introduces several states:- Free: When a BE node is added to the system, be is idle when it does not belong to any cluster.
- Use: When creating a cluster or expanding capacity is selected into a cluster, it is in use.
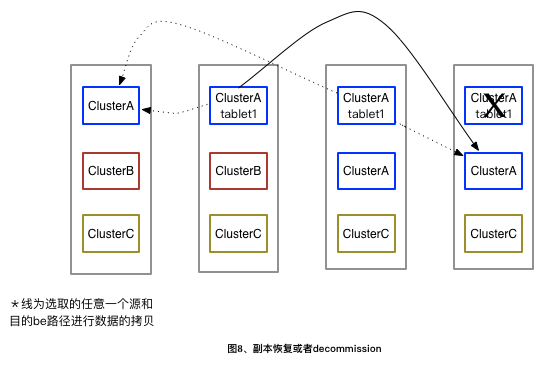
- Cluster decommission: If a shrinkage is performed, the be that is executing the shrinkage is in this state. After that, the be state becomes free.
- System decommission: be is offline. When the offline is completed, the be will be permanently deleted.
Only root users can check whether all be in the cluster is used through the cluster item in
SHOW PROC "/backends". To be free is to be idle, otherwise to be in use.SHOW BACKENDScan only see the nodes in the cluster. The following is a schematic diagram of the state changes of be nodes.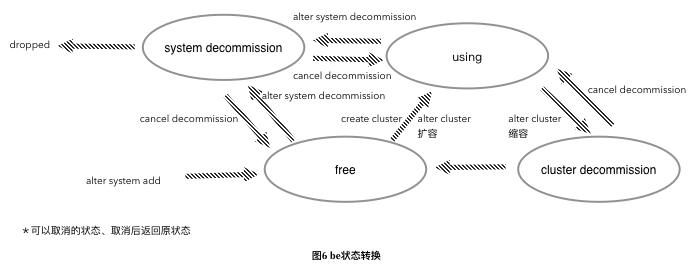
Creating Clusters
Only root users can create a cluster and specify any number of BE instances.
Supports selecting multiple instances on the same machine. The general principle of selecting instance is to select be on different machines as much as possible and to make the number of be used on all machines as uniform as possible.
For use, each user and DB belongs to a cluster (except root). To create user and db, you first need to enter a cluster. When a cluster is created, the system defaults to the manager of the cluster, the superuser account. Superuser has the right to create db, user, and view the number of be nodes in the cluster to which it belongs. All non-root user logins must specify a cluster, namely
user_name@cluster_name.Only root users can view all clusters in the system through `SHOW CLUSTER', and can enter different clusters through @ different cluster names. User clusters are invisible except root.
In order to be compatible with the old version of Doris, a cluster named default_cluster was built in, which could not be used when creating the cluster.
Cluster Expansion
The process of cluster expansion is the same as that of cluster creation. BE instance on hosts that are not outside the cluster is preferred. The selected principles are the same as creating clusters.
Cluster and Shrinkage CLUSTER DECOMMISSION
Users can scale clusters by setting instance num of clusters.
Cluster shrinkage takes precedence over Shrinking instances on hosts with the largest number of BE instances.
Users can also directly use
ALTER CLUSTER DECOMMISSION BACKENDto specify BE for cluster scaling.
Create table
To ensure high availability, each fragmented copy must be on a different machine. So when building a table, the strategy of choosing the be where the replica is located is to randomly select a be on each host. Then, the number of be copies needed is randomly selected from these be. On the whole, it can distribute patches evenly on each machine.
Therefore, adding a fragment that needs to create a 3-copy fragment, even if the cluster contains three or more instances, but only two or less hosts, still cannot create the fragment.
Load Balancing
The granularity of load balancing is cluster level, and there is no load balancing between clusters. However, the computing load is carried out at the host level, and there may be BE instances of different clusters on a host. In the cluster, the load is calculated by the number of fragments on each host and the utilization of storage, and then the fragments on the machine with high load are copied to the machine with low load (see the load balancing documents for details).
LINK DATABASE (Soft Chain)
Multiple clusters can access each other's data through a soft chain. The link level is dB for different clusters.
DB in other clusters is accessed by adding DB information of other clusters that need to be accessed in one cluster.
When querying the linked db, the computing and storage resources used are those of the cluster where the source DB is located.
DB that is soft-chained cannot be deleted in the source cluster. Only when the linked DB is deleted can the source DB be deleted. Deleting link DB will not delete source db.
MIGRATE DATABASE
DB can be physically migrated between clusters.
To migrate db, you must first link db. After migration, the data will migrate to the cluster where the linked DB is located, and after migration, the source DB will be deleted and the link will be disconnected.
Data migration reuses the process of replicating data in load balancing and replica recovery (see load balancing related documents for details). Specifically, after executing the
MIRAGTEcommand, Doris will modify the cluster of all copies of the source DB to the destination cluster in the metadata.Doris regularly checks whether machines in the cluster are balanced, replicas are complete, and redundant replicas are available. The migration of DB borrows this process, checking whether the be where the replica is located belongs to the cluster while checking the replica is complete, and if not, it is recorded in the replica to be restored. And when the duplicate is redundant to be deleted, it will first delete the duplicate outside the cluster, and then choose according to the existing strategy: the duplicate of the downtime be -> the duplicate of clone -> the duplicate of the backward version - > the duplicate on the host with high load, until the duplicate is not redundant.

BE process isolation
In order to isolate the actual cpu, IO and memory between be processes, we need to rely on the deployment of be. When deploying, you need to configure the CGroup on the periphery and write all the processes of be to be deployed to the cgroup. If the physical isolation of IO between the data storage paths of each be configuration requires different disks, there is no much introduction here.
