全新优化器介绍
研发背景
现代查询优化器面临更加复杂的查询语句、更加多样的查询场景等挑战。同时,用户也越来越迫切的希望尽快获得查询结果。旧优化器的陈旧架构,难以满足今后快速迭代的需要。基于此,我们开始着手研发现代架构的全新查询优化器。在更高效的处理当前 Doris 场景的查询请求的同时,提供更好的扩展性,为处理今后 Doris 所需面临的更复杂的需求打下良好的基础。
新优化器的优势
更智能
新优化器将每个 RBO 和 CBO 的优化点以规则的形式呈现。对于每一个规则,新优化器都提供了一组用于描述查询计划形状的模式,可以精确的匹配可优化的查询计划。基于此,新优化器可以更好的支持诸如多层子查询嵌套等更为复杂的查询语句。
同时新优化器的 CBO 基于先进的 Cascades 框架,使用了更为丰富的数据统计信息,并应用了维度更科学的代价模型。这使得新优化器在面对多表 Join 的查询时,更加得心应手。
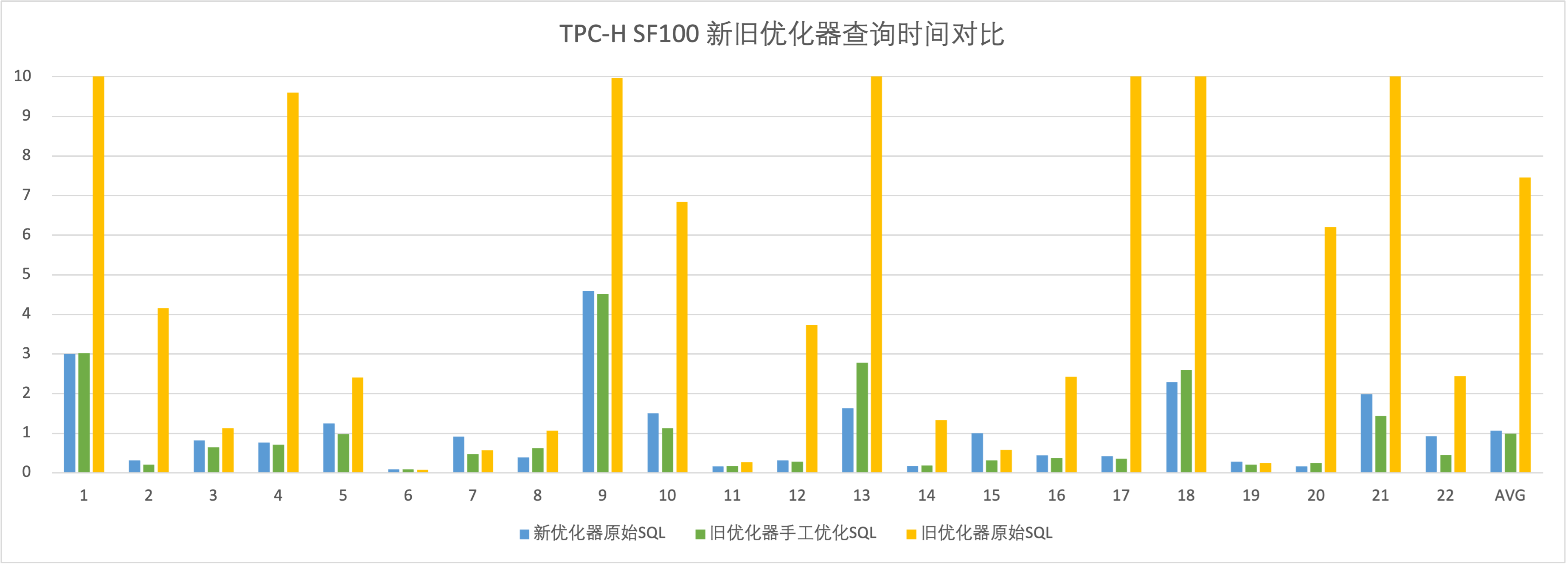
TPC-H SF100 查询速度比较。环境为 3BE,新优化器使用原始 SQL,执行 SQL 前收集了统计信息。旧优化器使用手工调优 SQL。可以看到,新优化器在无需手工优化查询的情况下,总体查询时间与旧优化器手工优化后的查询时间相近。
更健壮
新优化器的所有优化规则,均在逻辑执行计划树上完成。当查询语法语义解析完成后,变转换为一棵树状结构。相比于旧优化器的内部数据结构更为合理、统一。以子查询处理为例,新优化器基于新的数据结构,避免了旧优化器中众多规则对子查询的单独处理。进而减少了优化规则出现逻辑错误的可能。
更灵活
新优化器的架构设计更合理,更现代。可以方便地扩展优化规则和处理阶段。能够更为迅速的响应用户的需求。
使用方法
开启新优化器
SET enable_nereids_planner=true;
开启自动回退到旧优化器
SET enable_fallback_to_original_planner=true;
为了能够充分利用新优化器的 CBO 能力,强烈建议对查询延迟敏感的表,执行 analyze 语句,以收集列统计信息。
已知问题和暂不支持的功能
暂不支持的功能
如果开启了自动回退,则会自动回退到旧优化器执行
- Json、Array、Map、Struct 类型:查询的表含有以上类型,或者查询中的函数会输出以上类型
- DML:仅支持如下 DML:Insert Into Select, Update, Delete
- 带过滤条件的物化视图
- 别名函数
- Java UDF 和 HDFS UDF
- 高并发点查询优化
已知问题
- 不支持命中 Partition Cache
