日志存储与分析
日志是系统运行的详细记录,包含各种事件发生的主体、时间、位置、内容等关键信息。出于运维可观测、网络安全监控及业务分析等多重需求,企业通常需要将分散的日志采集起来,进行集中存储、查询和分析,以进一步从日志数据里挖掘出有价值的内容。
针对此场景,Apache Doris 提供了相应解决方案,针对日志场景的特点,增加了倒排索引和极速全文检索能力,极致优化写入性能和存储空间,使得用户可以基于 Apache Doris 构建开放、高性能、低成本、统一的日志存储与分析平台。
本文将围绕这一解决方案,介绍以下内容:
- 整体架构:说明基于 Apache Doris 构建的日志存储与分析平台的核心组成部分和基础架构。
- 特点与优势:说明基于 Apache Doris 构建的日志存储与分析平台的特点和优势。
- 操作指南:说明如何基于 Apache Doris 构建日志存储分析平台。
整体架构
基于 Apache Doris 构建的日志存储与分析平台的架构如下图:

此架构主要由 3 大部分组成:
- 日志采集和预处理:多种日志采集工具可以通过 HTTP APIs 将日志数据写入 Apache Doris。
- 日志存储和分析引擎:Apache Doris 提供高性能、低成本的统一日志存储,通过 SQL 接口提供丰富的检索分析能力。
- 日志分析和告警界面:多种日志检索分析通工具通过标准 SQL 接口查询 Apache Doris,为用户提供简单易用的界面。
特点与优势
基于 Apache Doris 构建的日志存储与分析平台的特点和优势如下:
- 高吞吐、低延迟日志写入:支持每天百 TB 级、GB/s 级日志数据持续稳定写入,同时保持延迟 1s 以内。
- 海量日志数据低成本存储:支持 PB 级海量存储,相对于 Elasticsearch 存储成本节省 60% 到 80%,支持冷数据存储到 S3/HDFS,存储成本再降 50%。
- 高性能日志全文检索分析:支持倒排索引和全文检索,日志场景常见查询(关键词检索明细、趋势分析等)秒级响应。
- 开放、易用的上下游生态:上游通过 Stream Load 通用 HTTP APIs 对接常见的日志采集系统和数据源 Logstash、Filebeat、Fluentbit、Kafka 等,下游通过标准 MySQL 协议和语法对接各种可视化分析 UI,比如可观测性 Grafana、BI 分析 Superset、类 Kibana 的日志检索 Doris WebUI。
高性能、低成本
经过 Benchmark 测试及生产验证,基于 Apache Doris 构建的日志存储与分析平台,性价比相对于 Elasticsearch 具有 5~10 倍的提升。Apache Doris 的性能优势,主要得益于全球领先的高性能存储和查询引擎,以及下面一些针对日志场景的专门优化:
- 写入吞吐提升:Elasticsearch 写入的性能瓶颈在于解析数据和构建倒排索引的 CPU 消耗。相比之下,Apache Doris 进行了两方面的写入优化:一方面利用 SIMD 等 CPU 向量化指令提升了 JSON 数据解析速度和索引构建性能;另一方面针对日志场景简化倒了排索引结构,去掉日志场景不需要的正排等数据结构,有效降低了索引构建的复杂度。同样的资源,Apache Doris 的写入性能是 Elasticsearch 的 3~5 倍。
- 存储成本降低:Elasticsearch 存储瓶颈在于正排、倒排、Docvalue 列存多份存储和通用压缩算法压缩率较低。相比之下,Apache Doris 在存储上进行了以下优化:去掉正排,缩减了 30% 的索引数据量;采用列式存储和 Zstandard 压缩算法,压缩比可达到 5~10 倍,远高于 Elasticsearch 的 1.5 倍;日志数据中冷数据访问频率很低,Apache Doris 冷热分层功能可以将超过定义时间段的日志自动存储到更低的对象存储中,冷数据的存储成本可降低 70% 以上。同样的原始数据,SelectDB 的存储成本只需要 Elasticsearch 的 20% 左右。
- 查询性能提升:Apache Doris 将全文检索的流程简化,跳过了相关性打分等日志场景不需要的算法,加速基础的检索性能。同时针对日志场景常见的查询,比如查询包含某个关键字的最新 100 条日志,在查询规划和执行上做专门的 TopN 动态剪枝等优化。
分析能力强
Apache Doris 支持标准 SQL、兼容 MySQL 协议和语法,因此基于 Apache Doris 构建的日志系统能够使用 SQL 进行日志分析,这使得日志系统具备以下优势:
- 简单易用:工程师和数据分析师对于 SQL 非常熟悉,经验可以复用,不需要学习新的技术栈即可快速上手。
- 生态丰富:MySQL 生态是数据库领域使用最广泛的语言,因此可以与 MySQL 生态的集成和应用无缝衔接。Doris 可以利用 MySQL 命令行与各种 GUI 工具、BI 工具等大数据生态结合,实现更复杂及多样化的数据处理分析需求。
- 分析能力强:SQL 语言已经成为数据库和大数据分析的事实标准,它具有强大的表达能力和功能,支持检索、聚合、多表 JOIN、子查询、UDF、逻辑视图、物化视图等多种数据分析能力。
Flexible Schema
下面是一个典型的 JSON 格式半结构化日志样例。顶层字段是一些比较固定的字段,比如日志时间戳(timestamp),日志来源(source),志所在机器(node),打日志的模块(component),日志级别(level),客户端请求标识(clientRequestId),日志内容(message),日志扩展属性(properties),基本上每条日志都会有。而扩展属性 properties 的内部嵌套字段 properties.size、properties.format 等是比较动态的,每条日志的字段可能不一样。
{
"timestamp": "2014-03-08T00:50:03.8432810Z",
"source": "ADOPTIONCUSTOMERS81",
"node": "Engine000000000405",
"level": "Information",
"component": "DOWNLOADER",
"clientRequestId": "671db15d-abad-94f6-dd93-b3a2e6000672",
"message": "Downloading file path: benchmark/2014/ADOPTIONCUSTOMERS81_94_0.parquet.gz",
"properties": {
"size": 1495636750,
"format": "parquet",
"rowCount": 855138,
"downloadDuration": "00:01:58.3520561"
}
}
Apache Doris 对 Flexible Schema 的日志数据提供了几个方面的支持:
- 对于顶层字段的少量变化,可以通过 Light Schema Change 发起 ADD / DROP COLUMN 增加 / 删除列,ADD / DROP INDEX 增加 / 删除索引,能够在秒级完成 Schema 变更。用户在日志平台规划时只需考虑当前需要哪些字段创建索引。
- 对于类似
properties的扩展字段,提供了原生半结构化数据类型VARIANT,可以写入任何 JSON 数据,自动识别 JSON 中的字段名和类型,并自动拆分频繁出现的字段采用列式存储,以便于后续的分析,还可以对VARIANT创建倒排索引,加快内部字段的查询和检索。
相对于 Elasticsearch 的 Dynamic Mapping,Apache Doris 的 Flexible Schema 有以下优势:
- 允许一个字段有多种类型,
VARIANT自动对字段类型做冲突处理和类型提升,更好地适应日志数据的迭代变化。 VARIANT自动将不频繁出现的字段合并成一个列存储,可避免字段、元数据、列过多导致性能问题。- 不仅可以动态加列,还可以动态删列、动态增加索引、动态删索引,无需像 Elasticsearch 在一开始对所有字段建索引,减少不必要的成本。
操作指南
第 1 步:评估资源
在部署集群之前,首先应评估所需服务器硬件资源,包括以下几个关键步骤:
- 评估写入资源:计算公式如下:
- 日增数据量 / 86400 s = 平均写入吞吐
- 平均写入吞吐 * 写入吞吐峰值 / 均值比 = 峰值写入吞吐
- 峰值写入吞吐 / 单核写入吞吐 = 峰值写入所需 CPU 核数
评估存储资源:计算公式为「日增数据量 / 压缩率 * 副本数 * 数据存储周期 = 所需存储空间」。
评估查询资源:查询的资源消耗随查询量和复杂度而异,建议初始预留 50% 的 CPU 资源用于查询,再根据实际测试情况进行调整。
汇总整合资源:由第 1 步和第 3 步估算出所需 CPU 核数后,除以单机 CPU 核数,估算出 BE 服务器数量,再根据 BE 服务器数量和第 2 步的结果,估算出每台 BE 服务器所需存储空间,然后分摊到 4~12 块数据盘,计算出单盘存储容量。
以每天新增 100 TB 数据量(压缩前)、7 倍压缩率、1 副本、热数据存储 3 天、冷数据存储 30 天、写入吞吐峰值 / 均值比 200%、单核写入吞吐 10 MB/s、查询预留 50% CPU 资源为例,可估算出:
- FE:3 台服务器,每台配置 16 核 CPU、64 GB 内存、1 块 100 GB SSD 盘
- BE:15 台服务器,每台配置 32 核 CPU、256 GB 内存、8 块 500 GB SSD 盘
- Amazon S3 存储空间:即为预估冷数据存储空间,430 TB
该例子中,各关键指标的值及具体计算方法可见下表:
| 关键指标(单位) | 值 | 说明 |
|---|---|---|
| 日增数据量(TB) | 100 | 根据实际需求填写 |
| 压缩率 | 7 | 一般为 5~10 倍(含索引),根据实际需求填写 |
| 副本数 | 1 | 根据实际需求填写,默认 1 副本,可选值:1,2,3 |
| 热数据存储周期(天) | 3 | 根据实际需求填写 |
| 冷数据存储周期(天) | 30 | 根据实际需求填写 |
| 总存储周期(天) | 33 | 算法:热数据存储周期 + 冷数据存储周期 |
| 预估热数据存储空间(TB) | 42.9 | 算法:日增数据量 / 压缩率 副本数 热数据存储周期 |
| 预估冷数据存储空间(TB) | 428.6 | 算法:日增数据量 / 压缩率 副本数 冷数据存储周期 |
| 写入吞吐峰值 / 均值比 | 200% | 根据实际需求填写,默认 200% |
| 单机 CPU 核数 | 32 | 根据实际需求填写,默认 32 核 |
| 平均写入吞吐(MB/s) | 1214 | 算法:日增数据量 / 86400 s |
| 峰值写入吞吐(MB/s) | 2427 | 算法:平均写入吞吐 * 写入吞吐峰值 / 均值比 |
| 峰值写入所需 CPU 核数 | 242.7 | 算法:峰值写入吞吐 / 单机 CPU 核数 |
| 查询预留 CPU 百分比 | 50% | 根据实际需求填写,默认 50% |
| 预估 BE 服务器数 | 15.2 | 算法:峰值写入所需 CPU 核数 / 单机 CPU 核数 /(1 - 查询预留 CPU 百分比) |
| 预估 BE 服务器数取整 | 15 | 算法:MAX (副本数,预估 BE 服务器数上取整) |
| 预估每台 BE 服务器存储空间(TB) | 4.03 | 算法:预估热数据存储空间 / 预估 BE 服务器数 /(1 - 30%),其中,30% 是存储空间预留值。建议每台 BE 服务器挂载 4~12 块数据盘,以提高 I/O 能力。 |
第 2 步:部署集群
完成资源评估后,可以开始部署 Apache Doris 集群,推荐在物理机及虚拟机环境中进行部署。手动部署集群,可参考 手动部署。
另,推荐使用 SelectDB Enterprise 推出的 Cluster Manager 工具部署集群,以降低整体部署成本。更多关于 Cluster Manager 的信息,可参考以下文档:
第 3 步:优化 FE 和 BE 配置
完成集群部署后,需分别优化 FE 和 BE 配置参数,以更加契合日志存储与分析的场景。
优化 FE 配置
在 fe/conf/fe.conf 目录下找到 FE 的相关配置项,并按照以下表格,调整 FE 配置。
| 需调整参数 | 说明 |
|---|---|
max_running_txn_num_per_db = 10000 | 高并发导入运行事务数较多,需调高参数。 |
streaming_lable_keep_max_second = 3600``label_keep_max_second = 7200 | 高频导入事务标签内存占用多,保留时间调短。 |
enable_round_robin_create_tablet = true | 创建 Tablet 时,采用 Round Robin 策略,尽量均匀。 |
tablet_rebalancer_type = partition | 均衡 Tablet 时,采用每个分区内尽量均匀的策略。 |
enable_single_replica_load = true | 开启单副本导入,多个副本只需构建一次索引,减少 CPU 消耗。 |
autobucket_min_buckets = 10 | 将自动分桶的最小分桶数从 1 调大到 10,避免日志量增加时分桶不够。 |
max_backend_heartbeat_failure_tolerance_count = 10 | 日志场景下 BE 服务器压力较大,可能短时间心跳超时,因此将容忍次数从 1 调大到 10。 |
更多关于 FE 配置项的信息,可参考 FE 配置项。
优化 BE 配置
在 be/conf/be.conf 目录下找到 BE 的相关配置项,并按照以下表格,调整 BE 配置。
| 模块 | 需调整参数 | 说明 |
|---|---|---|
| 存储 | storage_root_path = /path/to/dir1;/path/to/dir2;...;/path/to/dir12 | 配置热数据在磁盘目录上的存储路径。 |
| - | enable_file_cache = true | 开启文件缓存。 |
| - | file_cache_path = [{"path": "/mnt/datadisk0/file_cache", "total_size":53687091200, "query_limit": "10737418240"},{"path": "/mnt/datadisk1/file_cache", "total_size":53687091200,"query_limit": "10737418240"}] | 配置冷数据的缓存路径和相关设置,具体配置说明如下:path:缓存路径total_size:该缓存路径的总大小,单位为字节,53687091200 字节等于 50 GBquery_limit:单次查询可以从缓存路径中查询的最大数据量,单位为字节,10737418240 字节等于 10 GB |
| 写入 | write_buffer_size = 1073741824 | 增加写入缓冲区(buffer)的文件大小,减少小文件和随机 I/O 操作,提升性能。 |
| - | max_tablet_version_num = 20000 | 配合建表的 time_series compaction 策略,允许更多版本暂时未合并。 |
| - | enable_single_replica_load = true | 开启单副本写入,减少 CPU 消耗。与 FE 配置相同。 |
| Compaction | max_cumu_compaction_threads = 8 | 设置为 CPU 核数 / 4,意味着 CPU 资源的 1/4 用于写入,1/4 用于后台 Compaction,2/1 留给查询和其他操作。 |
| - | inverted_index_compaction_enable = true | 开启索引合并(index compaction),减少 Compaction 时的 CPU 消耗。 |
| - | enable_segcompaction = false enable_ordered_data_compaction = false | 关闭日志场景不需要的两个 Compaction 功能。 |
| 缓存 | disable_storage_page_cache = true inverted_index_searcher_cache_limit = 30% | 因为日志数据量较大,缓存(cache)作用有限,因此关闭数据缓存,调换为索引缓存(index cache)的方式。 |
| - | inverted_index_cache_stale_sweep_time_sec = 3600 index_cache_entry_stay_time_after_lookup_s = 3600 | 让索引缓存在内存中尽量保留 1 小时。 |
| - | enable_inverted_index_cache_on_cooldown = true enable_write_index_searcher_cache = false | 开启索引上传冷数据存储时自动缓存的功能。 |
| - | tablet_schema_cache_recycle_interval = 3600 segment_cache_capacity = 20000 | 减少其他缓存对内存的占用。 |
| 线程 | pipeline_executor_size = 24 doris_scanner_thread_pool_thread_num = 48 | 32 核 CPU 的计算线程和 I/O 线程配置,根据核数等比扩缩。 |
| - | scan_thread_nice_value = 5 | 降低查询 I/O 线程的优先级,保证写入性能和时效性。 |
| 其他 | string_type_length_soft_limit_bytes = 10485760 | 将 String 类型数据的长度限制调高至 10 MB。 |
| - | trash_file_expire_time_sec = 300 path_gc_check_interval_second = 900 path_scan_interval_second = 900 | 调快垃圾文件的回收时间。 |
更多关于 BE 配置项的信息,可参考 BE 配置项。
第 4 步:建表
由于日志数据的写入和查询都具备明显的特征,因此,在建表时按照本节说明进行针对性配置,以提升性能表现。
配置分区分桶参数
- 分区时,按照以下说明配置:
- 使用时间字段上的 Range 分区,并开启 动态分区,按天自动管理分区。
- 使用 Datetime 类型的时间字段作为 Key,在查询最新 N 条日志时有数倍加速。
- 分桶时,按照以下说明配置:
- 分桶数量大致为集群磁盘总数的 3 倍。
- 使用 Random 策略,配合写入时的 Single Tablet 导入,可以提升批量(Batch)写入的效率。
更多关于分区分桶的信息,可参考 分区分桶。
配置 Compaction 参数
按照以下说明配置 Compaction 参数:
- 使用 time_series 策略,以减轻写放大效应,对于高吞吐日志写入的资源写入很重要。
- 使用单副本 Compaction,减少多副本 Compaction 的开销。
建立和配置索引参数
按照以下说明操作:
- 对经常查询的字段建立索引。
- 对需要全文检索的字段,将分词器(parser)参数赋值为 unicode,一般能满足大部分需求。如有支持短语查询的需求,将 support_phrase 参数赋值为 true;如不需要,则设置为 false,以降低存储空间。
配置存储策略
按照以下说明操作:
- 对于热存储数据,如果使用云盘,可配置 1 副本;如果使用物理盘,则至少配置 2 副本。
- 配置
log_s3的存储位置,并设置log_policy_3day冷热数据分层策略,即在超过 3 天后将数据冷却至log_s3指定的存储位置。可参考以下代码:
CREATE DATABASE log_db;
USE log_db;
CREATE RESOURCE "log_s3"
PROPERTIES
(
"type" = "s3",
"s3.endpoint" = "your_endpoint_url",
"s3.region" = "your_region",
"s3.bucket" = "your_bucket",
"s3.root.path" = "your_path",
"s3.access_key" = "your_ak",
"s3.secret_key" = "your_sk"
);
CREATE STORAGE POLICY log_policy_3day
PROPERTIES(
"storage_resource" = "log_s3",
"cooldown_ttl" = "259200"
);
CREATE TABLE log_table
(
`ts` DATETIME,
`host` TEXT,
`path` TEXT,
`message` TEXT,
INDEX idx_host (`host`) USING INVERTED,
INDEX idx_path (`path`) USING INVERTED,
INDEX idx_message (`message`) USING INVERTED PROPERTIES("parser" = "unicode", "support_phrase" = "true")
)
ENGINE = OLAP
DUPLICATE KEY(`ts`)
PARTITION BY RANGE(`ts`) ()
DISTRIBUTED BY RANDOM BUCKETS 250
PROPERTIES (
"dynamic_partition.enable" = "true",
"dynamic_partition.create_history_partition" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-30",
"dynamic_partition.end" = "1",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "250",
"dynamic_partition.replication_num" = "1", -- 存算分离不需要
"replication_num" = "1" -- 存算分离不需要
"enable_single_replica_compaction" = "true", -- 存算分离不需要
"storage_policy" = "log_policy_3day", -- 存算分离不需要
"compaction_policy" = "time_series"
);
第 5 步:采集和查询日志
完成建表后,可进行日志采集、查询和分析。
日志采集
Apache Doris 提供开放、通用的 Stream HTTP APIs,通过这些 APIs,你可与常用的日志采集器打通,包括 Logstash、Filebeat、Kafka 等,从而开展日志采集工作。本节介绍了如何使用 Stream HTTP APIs 对接日志采集器。
对接 Logstash
按照以下步骤操作:
- 下载并安装 Logstash Doris Output 插件。你可选择以下两种方式之一:
- 直接下载:点此下载。
- 从源码编译,并运行下方命令安装:
./bin/logstash-plugin install logstash-output-doris-1.0.0.gem
- 配置 Logstash。需配置以下参数:
logstash.yml:配置 Logstash 批处理日志的条数和时间,用于提升数据写入性能。
pipeline.batch.size: 1000000
pipeline.batch.delay: 10000
logstash_demo.conf:配置所采集日志的具体输入路径和输出到 Apache Doris 的设置。
input {
file {
path => "/path/to/your/log"
}
}
<br />output {
doris {
http_hosts => \[ "<http://fehost1:http_port>", "<http://fehost2:http_port>", "<http://fehost3:http_port"\>]
user => "your_username"
password => "your_password"
db => "your_db"
table => "your_table"
\# doris stream load http headers
headers => {
"format" => "json"
"read_json_by_line" => "true"
"load_to_single_tablet" => "true"
}
\# field mapping: doris fileld name => logstash field name
\# %{} to get a logstash field, \[\] for nested field such as \[host\]\[name\] for host.name
mapping => {
"ts" => "%{@timestamp}"
"host" => "%{\[host\]\[name\]}"
"path" => "%{\[log\]\[file\]\[path\]}"
"message" => "%{message}"
}
log_request => true
log_speed_interval => 10
}
}
- 按照下方命令运行 Logstash,采集日志并输出至 Apache Doris。
./bin/logstash -f logstash_demo.conf
更多关于 Logstash 配置和使用的说明,可参考 Logstash Doris Output Plugin。
对接 Filebeat
按照以下步骤操作:
- 获取支持输出至 Apache Doris 的 Filebeat 二进制文件。可 点此下载 或者从 Apache Doris 源码编译。
- 配置 Filebeat。需配置以下参数:
filebeat_demo.yml:配置所采集日志的具体输入路径和输出到 Apache Doris 的设置。# input
filebeat.inputs:
- type: log
enabled: true
paths:
- /path/to/your/log
# multiline 可以将跨行的日志(比如 Java stacktrace)拼接起来
multiline:
type: pattern
# 效果:以 yyyy-mm-dd HH:MM:SS 开头的行认为是一条新的日志,其他都拼接到上一条日志
pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}'
negate: true
match: after
skip_newline: true
processors:
# 用 js script 插件将日志中的 \t 替换成空格,避免 JSON 解析报错
- script:
lang: javascript
source: >
function process(event) {
var msg = event.Get("message");
msg = msg.replace(/\t/g, " ");
event.Put("message", msg);
}
# 用 dissect 插件做简单的日志解析
- dissect:
# 2024-06-08 18:26:25,481 INFO (report-thread|199) [ReportHandler.cpuReport():617] begin to handle
tokenizer: "%{day} %{time} %{log_level} (%{thread}) [%{position}] %{content}"
target_prefix: ""
ignore_failure: true
overwrite_keys: true
# queue and batch
queue.mem:
events: 1000000
flush.min_events: 100000
flush.timeout: 10s
# output
output.doris:
fenodes: [ "http://fehost1:http_port", "http://fehost2:http_port", "http://fehost3:http_port" ]
user: "your_username"
password: "your_password"
database: "your_db"
table: "your_table"
# output string format
## %{[agent][hostname]} %{[log][file][path]} 是filebeat自带的metadata
## 常用的 filebeat metadata 还是有采集时间戳 %{[@timestamp]}
## %{[day]} %{[time]} 是上面 dissect 解析得到字段
codec_format_string: '{"ts": "%{[day]} %{[time]}", "host": "%{[agent][hostname]}", "path": "%{[log][file][path]}", "message": "%{[message]}"}'
headers:
format: "json"
read_json_by_line: "true"
load_to_single_tablet: "true"
- 按照下方命令运行 Filebeat,采集日志并输出至 Apache Doris。
chmod +x filebeat-doris-1.0.0
./filebeat-doris-1.0.0 -c filebeat_demo.yml
更多关于 Filebeat 配置和使用的说明,可参考 Beats Doris Output Plugin。
对接 Kafka
将 JSON 格式的日志写入 Kafka 的消息队列,创建 Kafka Routine Load,即可让 Apache Doris 从 Kafka 主动拉取数据。
可参考如下示例。其中,property.\* 是 Librdkafka 客户端相关配置,根据实际 Kafka 集群情况配置。
\-- 准备好kafka集群和topic log_\_topic_
\-- 创建routine load,从kafka log_\_topic_将数据导入log_table表
CREATE ROUTINE LOAD load_log_kafka ON log_db.log_table
COLUMNS(ts, clientip, request, status, size)
PROPERTIES (
"max_batch_interval" = "10",
"max_batch_rows" = "1000000",
"max_batch_size" = "109715200",
"load_to_single_tablet" = "true",
"timeout" = "600",
"strict_mode" = "false",
"format" = "json"
)
FROM KAFKA (
"kafka_broker_list" = "host:port",
"kafka_topic" = "log_\_topic_",
"property.group.id" = "your_group_id",
"property.security.protocol"="SASL_PLAINTEXT",
"property.sasl.mechanism"="GSSAPI",
"property.sasl.kerberos.service.name"="kafka",
"property.sasl.kerberos.keytab"="/path/to/xxx.keytab",
"property.sasl.kerberos.principal"="<xxx@yyy.com>"
);
-- 查看routine的状态
SHOW ROUTINE LOAD;
更多关于 Kafka 配置和使用的说明,可参考 Routine Load。
使用自定义程序采集日志
除了对接常用的日志采集器以外,你也可以自定义程序,通过 HTTP API Stream Load 将日志数据导入 Apache Doris。参考以下代码:
curl \\
\--location-trusted \\
\-u username:password \\
\-H "format:json" \\
\-H "read_json_by_line:true" \\
\-H "load_to_single_tablet:true" \\
\-H "timeout:600" \\
\-T logfile.json \\
http://fe_host:fe_http_port/api/log_db/log_table/\_stream_load
在使用自定义程序时,需注意以下关键点:
- 使用 Basic Auth 进行 HTTP 鉴权,用命令
echo -n 'username:password' | base64进行计算。 - 设置 HTTP header "format:json",指定数据格式为 JSON。
- 设置 HTTP header "read_json_by_line:true",指定每行一个 JSON。
- 设置 HTTP header "load_to_single_tablet:true",指定一次导入写入一个分桶减少导入的小文件。
- 建议写入客户端一个 Batch 的大小为 100MB ~ 1GB。如果你使用的是 Apache Doris 2.1 及更高版本,需通过服务端 Group Commit 功能,降低客户端 Batch 大小。
日志查询
Apache Doris 支持标准 SQL,因此,你可以通过 MySQL 客户端或者 JDBC 等方式连接到集群,执行 SQL 进行日志查询。参考以下命令:
mysql -h fe_host -P fe_mysql_port -u your_username -Dyour_db_name
下方列出常见的 5 条 SQL 查询命令,以供参考:
- 查看最新的 10 条数据
SELECT \* FROM your_table_name ORDER BY ts DESC LIMIT 10;
- 查询
host为8.8.8.8的最新 10 条数据
SELECT \* FROM your_table_name WHERE host = '8.8.8.8' ORDER BY ts DESC LIMIT 10;
- 检索请求字段中有
error或者404的最新 10 条数据。其中,MATCH_ANY是 Apache Doris 全文检索的 SQL 语法,用于匹配参数中任一关键字。
SELECT \* FROM your_table_name WHERE message MATCH_ANY 'error 404'
ORDER BY ts DESC LIMIT 10;
- 检索请求字段中有
image和faq的最新 10 条数据。其中,MATCH_ALL是 Apache Doris 全文检索的 SQL 语法,用于匹配参数中所有关键字。
SELECT \* FROM your_table_name WHERE message MATCH_ALL 'image faq'
ORDER BY ts DESC LIMIT 10;
- 检索请求字段中有
image和faq的最新 10 条数据。其中,MATCH_PHRASE是 Apache Doris 全文检索的 SQL 语法,用于匹配参数中所有关键字,并且要求顺序一致。在下方例子中,a image faq b能匹配,但是a faq image b不能匹配,因为image和faq的顺序与查询不一致。
SELECT \* FROM your_table_name WHERE message MATCH_PHRASE 'image faq'
ORDER BY ts DESC LIMIT 10;
可视化日志分析
基于 Apache Doris 构建的 SelectDB Enterprise Core 提供了名为 Doris WebUI 的数据开发平台,Doris WebUI 包含了类 Kibana Discover 的日志检索分析界面,提供直观、易用的探索式日志分析交互,如下图所示:
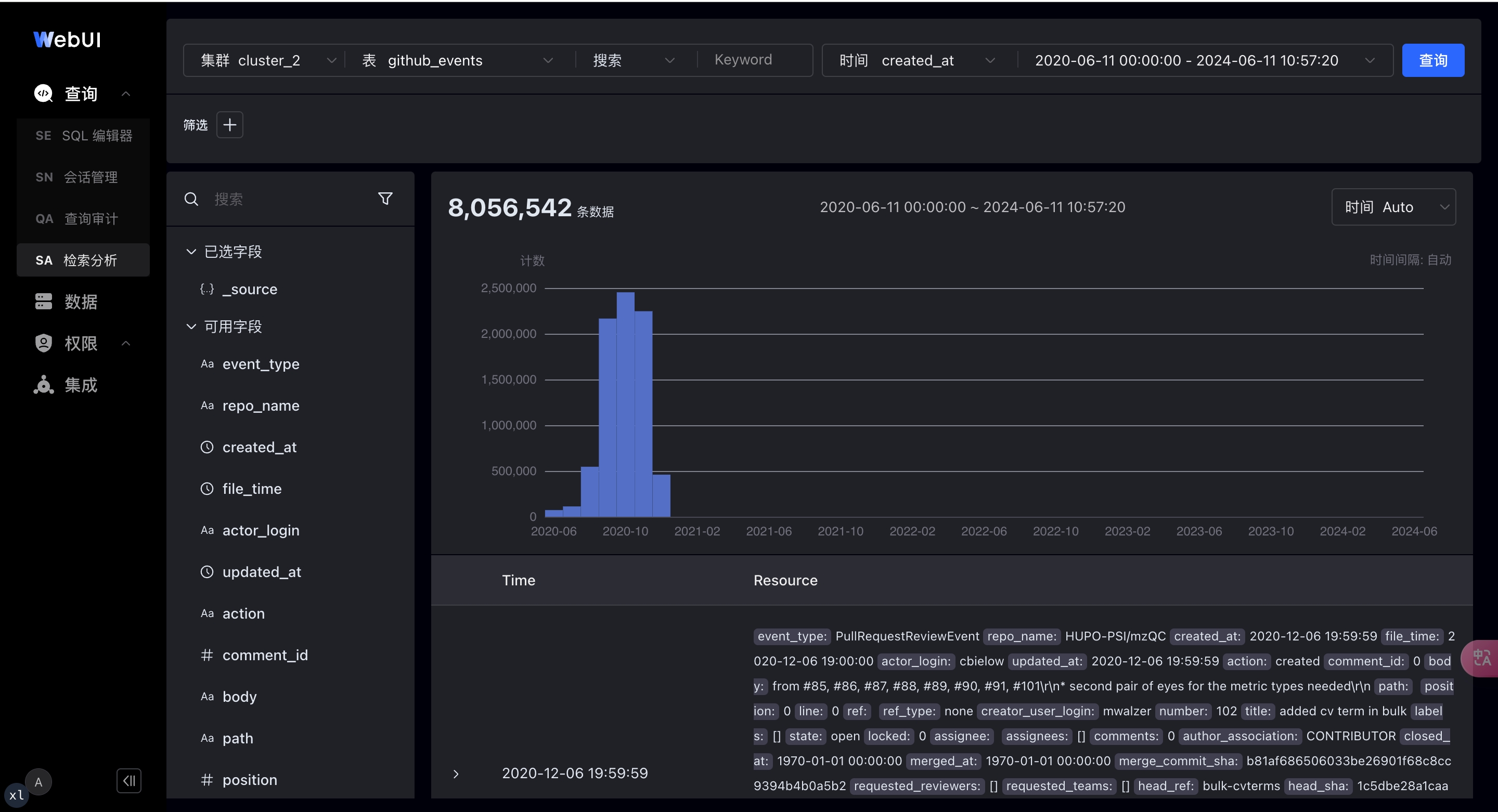
在此界面上,Doris WebUI 主要支持以下功能:
- 支持全文检索和 SQL 两种模式
- 支持时间框和直方图上选择查询日志的时间段
- 支持信息丰富的日志明细展示,还可以展开成 JSON 或表格
- 在日志数据上下文交互式点击增加和删除筛选条件
- 搜索结果的字段 Top 值展示,便于发现异常值和进一步下钻分析
你可以 点此下载 SelectDB Enterprise Core,完成 安装 后,即可使用 Doris WebUI 登录数据库。更多关于如何使用 Doris WebUI 的信息,可参考 WebUI。
