Release 2.0-Beta
We are excited to announce the release of Apache Doris 2.0 Beta. We would like to extend our heartfelt thanks to the 255 Apache Doris Contributors who have committed over 3500 bug fixes and optimizations altogether. You are the driving force behind all the new features and performance leap!
Download: https://doris.apache.org/download
GitHub source code: https://github.com/apache/doris/tree/branch-2.0
In the middle of 2023, we are half way on our roadmap and many steps closer to our visions that we put forward on Doris Summit 2022:
We want to build Apache Doris into an all-in-one platform that can serve most of our users' needs so as to maximize their productivity while inducing the least development and maintainence costs. Specifically, it should be capable of data analytics in multiple scenarios, support both online and offline workloads, and deliver lightning performance in both high-throughput interactive analysis and high-concurrency point queries. Also, in response to industry trends, it should be able to provide seamless analytic services across heterogenous data sources, and unified management services for semi-structured and unstructured data.
Taking on these great visions means a path full of hurdles. We need to figure out answers to all these difficult questions:
- How to ensure real-time data writing without compromising query service stability?
- How to ensure online service continuity during data updates and table schema changes?
- How to store and analyze structured and semi-structured data efficiently in one place?
- How to handle multiple workloads (point queries, reporting, ad-hoc queries, ETL/ELT, etc.) at the same time and guarantee isolation of them?
- How to enable efficient execution of complicated SQLs, stability of big queries, and observability of execution?
- How to integrate and access data lakes and many heterogenous data sources more easily?
- How to improve query performance while largely reducing storage and computation costs?
We believe that life is miserable for either the developers or the users, so we decided to tackle more challenges so that our users would suffer less. Now we are happy to announce our progress with Apache Doris 2.0 Beta. These are what you can expect from this new version:
A 10 times Performance Increase
High performance is what our users identify us with. It has been repeatedly proven by the test results of Apache Doris on ClickBench and TPC-H benchmarks during the past year. But there remain some differences between benchmarking and real-life application:
- Benchmarking simplifies and abstracts real-world scenarios so it might not cover the complex query statements that are frequently seen in data analytics.
- Query statements in benchmarking are often fine-tuned, but in real life, fine-tuning is just too demanding, exhausting, and time-consuming.
That's why we introduced a brand new query optimizer: Nereids. With a richer statistical base and the advanced Cascades framework, Nereids is capable of self-tuning in most query scenarios, so users can expect high performance without any fine-tuning or SQL rewriting. What's more, it supports all 99 SQLs in TPC-DS.
Testing on 22 TPC-H SQLs showed that Nereids, with no human intervention, brought an over 10-time performance increase compared to the old query optimizer. Similar results were reported by dozens of users who have tried Apache Doris 2.0 Alpha in their business scenarios. It has really freed engineers from the burden of fine-tuning.
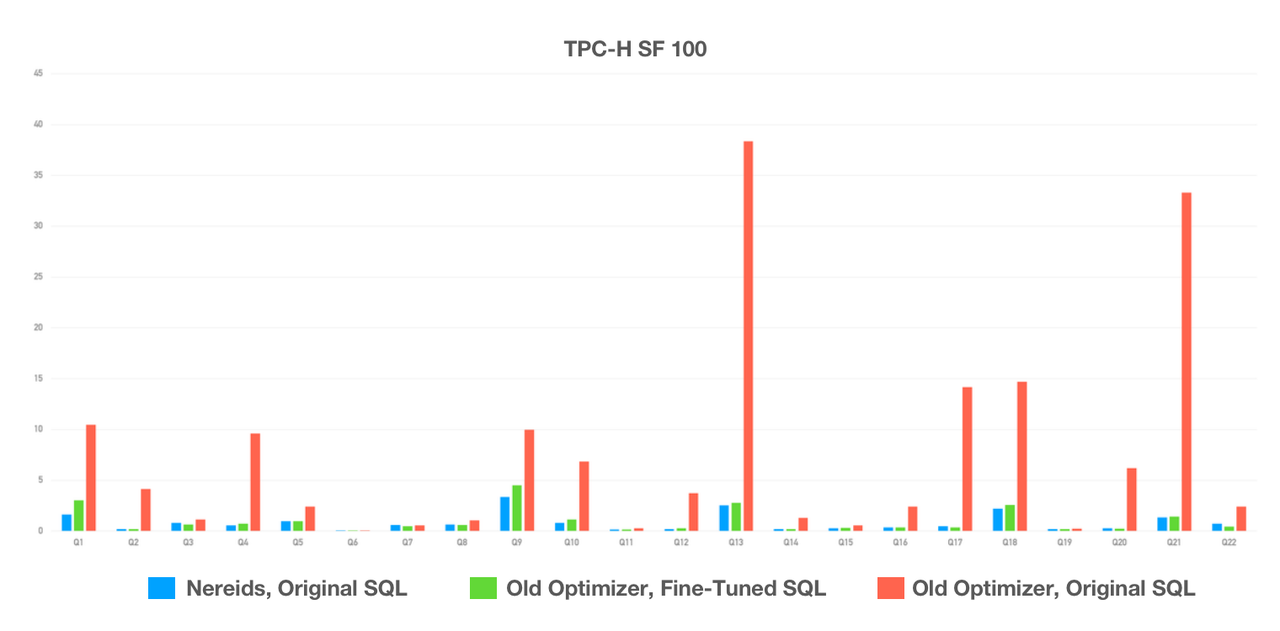
Documentation: https://doris.apache.org/docs/dev/query-acceleration/nereids/
Nerieds is enabled by default in Apache Doris 2.0 Beta: SET enable_nereids_planner=true.
Support for a Wider Range of Analytic Scenarios
A 10 times more cost-effective log analysis solution
From a simple OLAP engine for real-time reporting to a data warehouse that is capable of ETL/ELT and more, Apache Doris has been pushing its boundaries. With version 2.0, we are making breakthroughs in log analysis.
The common log analytic solutions within the industry are basically different tradeoffs between high writing throughput, low storage cost, and fast text retrieval. But Apache Doris 2.0 allows you to have them all. It has inverted index that allows full-text searches on strings and equivalence/range queries on numerics/datetime. Comparison tests with the same datasets in the same hardware environment showed that Apache Doris was 4 times faster than Elasticsearch in log data writing, 2 times faster in log queries, and cost only 20% of the storage space that Elasticsearch used.

We are also making advancements in multi-model data analysis. Apache Doris 2.0 supports two new data types: Map and Struct, as well as the quick writing, functional analysis, and nesting of them.
Read more: https://doris.apache.org/blog/Inverted%20Index
High-concurrency data serving
In scenarios such as e-commerce order queries and express tracking, there will be a huge number of end data users inputing queries for a small piece of data simultaneously. These are high-concurrency point queries, which can bring huge pressure on the system. A traditional solution is to introduce Key-Value stores like Apache HBase for such queries, and Redis as a cache layer to ease the burden, but that means redundant storage and higher maintainence costs.
For a column-oriented DBMS like Apache Doris, the I/O usage of point queries will be multiplied. We need neater execution. Thus, we introduced row storage format and row cache to increase row reading efficiency, short-circuit plans to speed up data retrieval, and prepared statements to reduce frontend overheads.
After these optimizations, Apache Doris 2.0 reached a concurrency level of 30,000 QPS per node on YCSB on a 16 Core 64G cloud server with 4×1T hard drives, representing an improvement of 20 times compared to older versions. This makes Apache Doris a good alternative to HBase in high-concurrency scenarios.
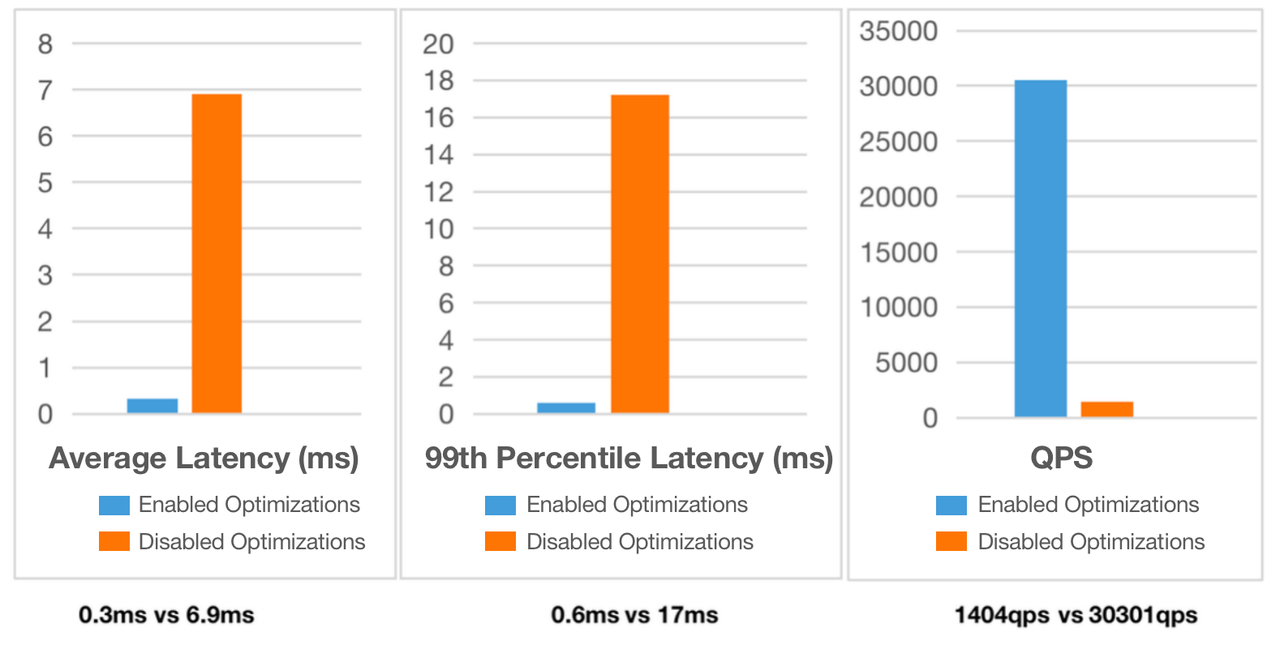
Doc: https://doris.apache.org/blog/High_concurrency
Enhanced data lakehouse capabilities
In Apache Doris 1.2, we introduced Multi-Catalog to support the auto-mapping and auto-synchronization of data from heterogeneous sources. After optimizations in data reading, execution engine, and query optimizer, Doris 1.2 delivered a 3~5 times faster query performance than Presto/Trino in standard tests.
In Apache Doris 2.0, we extended the list of data sources supported and conducted optimizations according to the actual production environment of users.
More data sources supported
- Supported snapshot queries on Hudi Copy-on-Write tables and read optimized queries on Hudi Merge-on-Read tables; The support for incremental queries and snapshot queries on Merge-on-Read tables is under plan.
- Supported connection to Oceanbase via JDBC Catalog, prolonging the list of supported relational databases which include MySQL, PostgreSQL, Oracle, SQLServer, Doris, ClickHouse, SAP HANA, and Trino/Presto.
Data Privilege Control
- Supported authorization for Hive Catalog via Apache Range; Supported extensible privilege authorization plug-ins to allow user-defined authorization method on any catalog.
Performance improvement
Accelerated reading of flat tables and large numbers of small files; improved query speed by dozens of times; reduced reading overhead by techniques such as full loading of small files, I/O coalescing, and data pre-fetching.
Increased query speed on ORC/Parquet files by 100% compared to version 1.2.
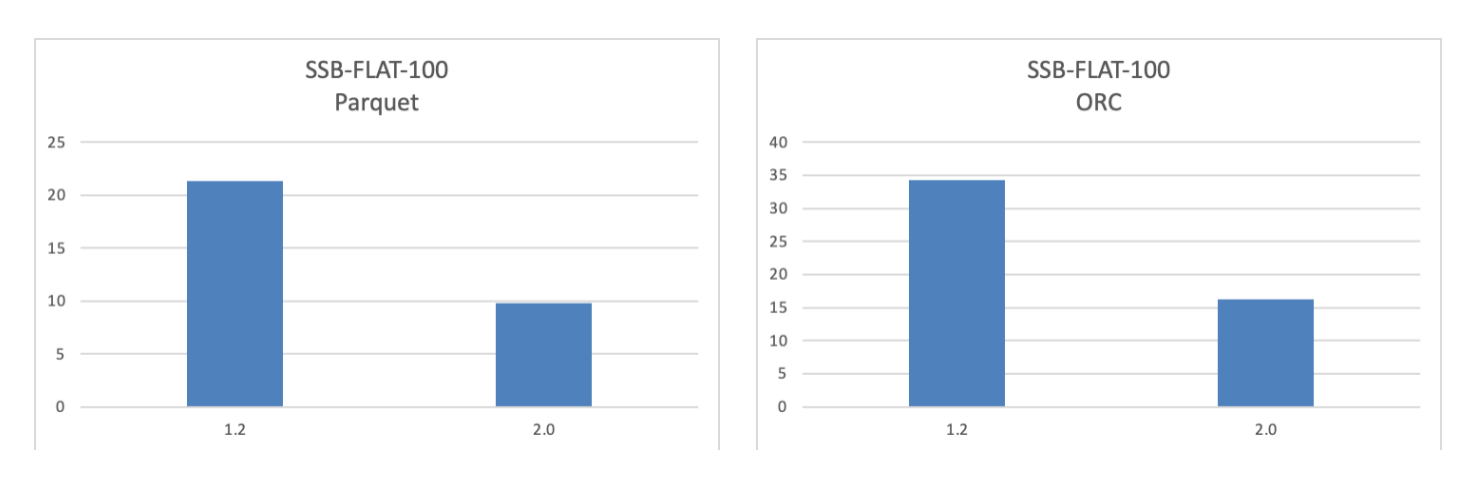
Supported local caching of lakehouse data. Users can cache data from HDFS or object storage in local disks to speed up queries involving the same data. In the case of cache hits, querying lakehouse data will be as quick as querying internal data in Apache Doris.
Supported collection of external table statistics. Users can obtain statistics about their specified external tables via the Analyze statement so that Nereids can fine-tune the query plan for complicated SQLs more efficiently.
Improved data writeback speed of JDBC Catalog. By way of PrepareStmt and other batch methods, users can write data back to relational databases such as MySQL and Oracle via the INSERT INTO command much faster.
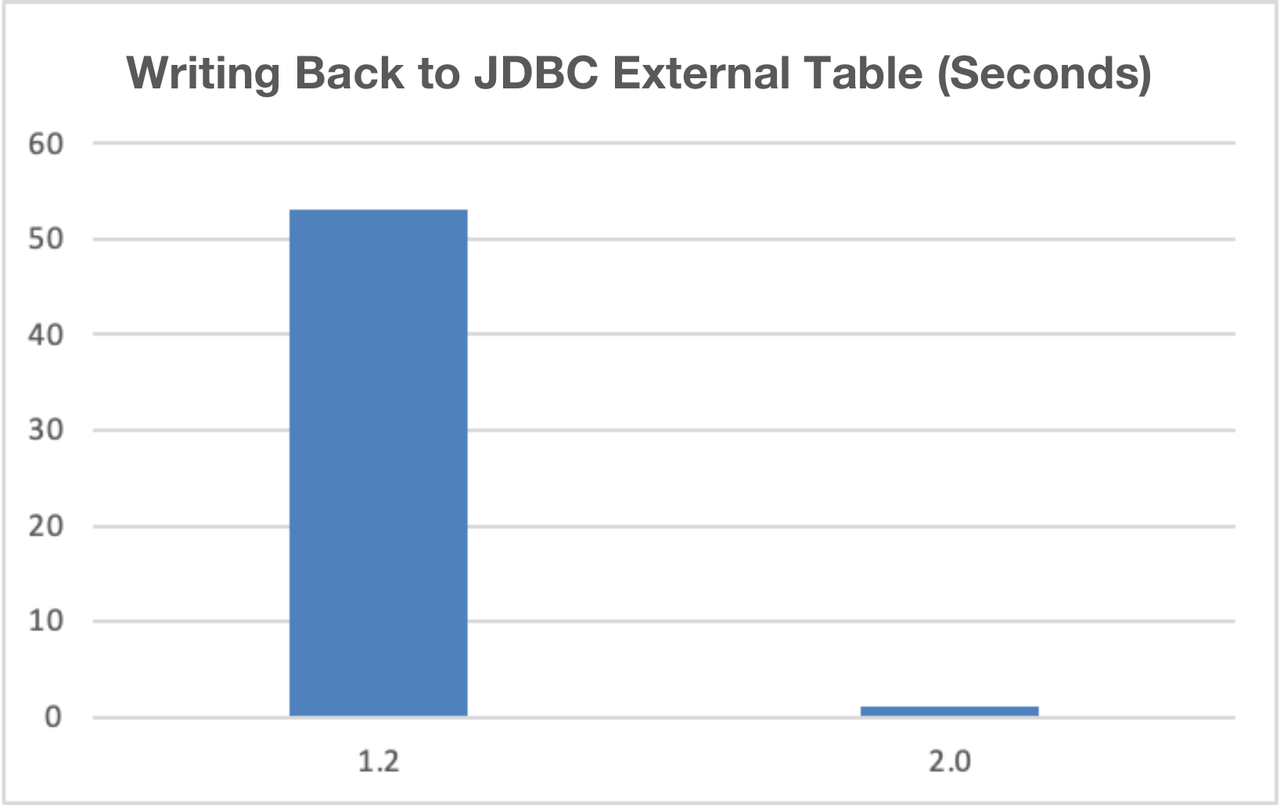
A Unified Platform for Multiple Analytic Workloads
A self-adaptive parallel execution model
With the expansion of user base, Apache Doris is undertaking more and more analytic workloads while handling larger and larger data sizes. A big challenge is to ensure high execution efficiency for all these workloads and avoid resource preemption.
Older versions of Apache Doris had a volcano-based execution engine. To give full play to all the machines and cores, users had to set the execution concurrency themselves (for example, change parallel_fragment_exec_instance_num from the default value 1 to 8 or 16). But problems existed when Doris had to deal with multiple queries at the same time:
- Instance operators took up the threads and the query tasks didn't get executed. Logical deadlocks occurred.
- Instance threads were scheduled by a system scheduling mechanism and the switching between threads brought extra overheads.
- When processing various analytic workloads, instance threads might fight for CPU resources so queries and tenants might interrupt each other.
Apache 2.0 brought in a Pipeline execution engine to solve these problems. In this engine, the execution of queries are driven by data. The blocking operators in all the query execution processes are split into pipelines. Whether a pipeline gets an execution thread depends on whether its data is ready. As a result:
- The Pipeline execution model splits the query execution plan into pipeline tasks based on the blocking logic and asynchronizes the blocking operations, so no instance is going to take up a single thread for a long time.
- It allows users to manage system resources more flexibly. They can take different scheduling strategies to assign CPU resources to various queries and tenants.
- It also pools data from all buckets, so the number of instances will not be limited by the number of buckets, and the system doesn't have to frequently create and destroy threads.
With the Pipeline execution engine, Apache Doris is going to offer faster queries and higher stability in hybrid workload scenarios.
Doc: https://doris.apache.org/docs/dev/query-acceleration/pipeline-execution-engine/
The Pipeline execution engine is enabled by default in Apache Doris 2.0: Set enable_pipeline_engine = true. parallel_pipeline_task_num represents the number of pipeline tasks that are parallelly executed in SQL queries. The default value of it is 0, and users can change the value as they need. For those who are upgrading to Apache Doris 2.0 from an older version, it is recommended to set the value of parallel_pipeline_task_num to that of parallel_fragment_exec_instance_num in the old version.
Workload management
Based on the Pipeline execution engine, Apache Doris 2.0 divides the workloads into Workload Groups for fine-grained management of memory and CPU resources.
By relating a query to a Workload Group, users can limit the percentage of memory and CPU resources used by one query on the backend nodes and configure memory soft limits for resource groups. When there is a cluster resource shortage, the system will kill the largest memory-consuming tasks; when there is sufficient cluster resources, once the Workload Groups use more resources than expected, the idle cluster resources will be shared among multiple Workload Groups and the system memory will still be used to ensure stable execution of queries.
create workload group if not exists etl_group
properties (
"cpu_share"="10",
"memory_limit"="30%",
"max_concurrency" = "10",
"max_queue_size" = "20",
"queue_timeout" = "3000"
);
You can check the existing Workload Group via the Show command:
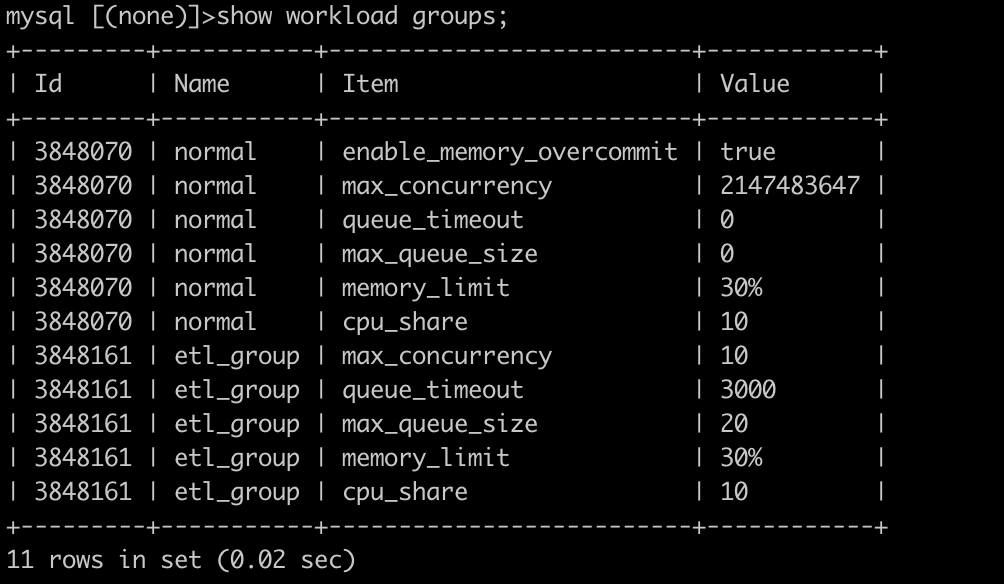
Query queue
When creating a Workload Group, users can set a maximum query number for it. Queries beyond that limit will wait for execution in the query queue.
max_concurrency: the maximum number of queries allowed by the current Workload Groupmax_queue_size: the length of query queue. After all spots are filled, any new queries will be rejected.queue_timeout: the waiting time of a query in a queue, measured in miliseconds. If a queue has been waiting for longer than this limit, it will be rejected.
Doc: https://doris.apache.org/docs/dev/admin-manual/workload-group/
Elastic Scaling and Storage-Compute Separation
When it comes to computation and storage resources, what do users want?
- Elastic scaling of computation resources: Scale up resources quickly in peak times to increase efficiency and scale down in valley times to reduce costs.
- Lower storage costs: Use low-cost storage media and separate storage from computation.
- Separation of workloads: Isolate the computation resources of different workloads to avoid preemption.
- Unified management of data: Simply manage catalogs and data in one place.
To separate storage and computation is a way to realize elastic scaling of resources, but it demands more efforts in maintaining storage stability, which determines the stability and continuity of OLAP services. To ensure storage stability, we introduced mechanisms including cache management, computation resource management, and garbage collection.
In this respect, we divide our users into three groups after investigation:
- Users with no need for resource scaling
- Users requiring resource scaling, low storage costs, and workload separation from Apache Doris
- Users who already have a stable large-scale storage system and thus require an advanced compute-storage-separated architecture for efficient resource scaling
Apache Doris 2.0 provides two solutions to address the needs of the first two types of users.
Compute nodes. We introduced stateless compute nodes in version 2.0. Unlike the mix nodes, the compute nodes do not save any data and are not involved in workload balancing of data tablets during cluster scaling. Thus, they are able to quickly join the cluster and share the computing pressure during peak times. In addition, in data lakehouse analysis, these nodes will be the first ones to execute queries on remote storage (HDFS/S3) so there will be no resource competition between internal tables and external tables.
Hot-cold data separation. Hot/cold data refers to data that is frequently/seldom accessed, respectively. Generally, it makes more sense to store cold data in low-cost storage. Older versions of Apache Doris support lifecycle management of table partitions: As hot data cooled down, it would be moved from SSD to HDD. However, data was stored with multiple replicas on HDD, which was still a waste. Now, in Apache Doris 2.0, cold data can be stored in object storage, which is even cheaper and allows single-copy storage. That reduces the storage costs by 70% and cuts down the computation and network overheads that come with storage.
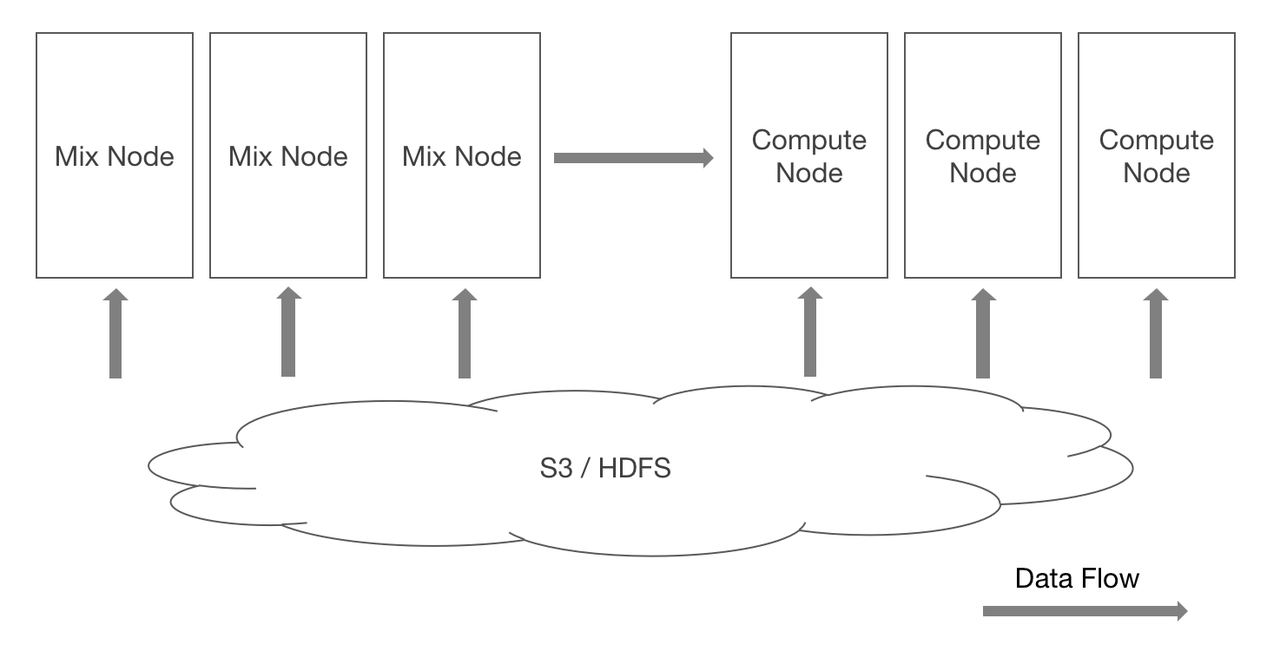
For the third type of users, the SelectDB team is going to contribute the SelectDB Cloud Compute-Storage-Separation solution to the Apache Doris project. The performance and stability of this solution has stood the test of hundreds of companies in their production environment. The merging of the solution to Apache Doris is underway.
Faster, Stabler, and Smarter Data Writing
Higher speed in data writing
As part of our continuing effort to strengthen the real-time analytic capability of Apache Doris, we have improved the end-to-end real-time data writing of version 2.0:
- When tested with the TPC-H 100G standard dataset, Apache Doris 2.0 reached a data loading speed of over 550MB/s for a single node with its
insert into selectmethod, which was a 200% increase. In triple-replica import of 144G data, it delivered a single-node data loading speed of 121MB/s via the Stream Load method, up 400% in system throughput. - We have introduced single-replica data loading into version 2.0. Apache Doris guarantees high data reliability and system availability by its multi-replica mechanism, but multi-replica writing also multiplies the CPU and memory usage. Now Apache Doris only writes one data copy to the memory, and then it synchronizes the storage file to other copies, so it can save a lot of the computation resources. In large data ingestion, the single-replica loading method can accelerate data ingestion by 200%.
Greater stability in high-concurrency data writing
The merging of small files, write amplification, and the consequential disk I/O and CPU overheads are often the sources of system instability. Hence, we introduced Vertical Compaction and Segment Compaction in version 2.0 to eliminate OOM errors in compaction and avoid the generation of too many segment files during data writing. After such improvements, Apache Doris can write data 50% faster while using only 10% of the memory that it previously used.
Read more: https://doris.apache.org/blog/Compaction
Auto-synchronization of table schema
The latest Flink-Doris-Connector allows users to synchronize the whole database (such as MySQL) to Apache Doris by one simple step. According to our test results, one single synchronization task can undertake the real-time concurrent writing of thousands of tables. Apache Doris has automated the updating of upstream table schema and data so users no longer need to go through a complicated synchronization procedure. Also, changes in the upstream data schema will be automatically captured and dynamically updated to Apache Doris in a seamless manner.
Support for Partial Column Update in the Unique Key Model
Apache Doris 1.2 realized real-time writing and quick query execution at the same time with the Merge-on-Write mechanism in the Unique Key Model. Now in version 2.0, we have further improved the Unique Key Model. It supports partial column update so when ingesting multiple source tables, users don't have to merge them into one flat table in advance.
On this basis, we have also enhanced the capability of Merge-on-Write. Apache Doris 2.0 is 50% faster than Apache Doris 1.2 in large data writing and 10 times faster in high-concurrency data writing. A parallel processing mechanism is available to avoid "publish timeout" (E-3115), and a more efficient compaction mechanism is in place to prevent "too many versions" (E-235). All this allows users to replace Merge-on-Read with Merge-on-Write in more scenarios. Plus, partial column update makes the execution of the UPDATE and DELETE statements less costly.
The execution of partial column update is simple.
Example (Stream Load):
Suppose that you have the following table schema:
mysql> desc user_profile;
+------------------+-----------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------------+-----------------+------+-------+---------+-------+
| id | INT | Yes | true | NULL | |
| name | VARCHAR(10) | Yes | false | NULL | NONE |
| age | INT | Yes | false | NULL | NONE |
| city | VARCHAR(10) | Yes | false | NULL | NONE |
| balance | DECIMALV3(9, 0) | Yes | false | NULL | NONE |
| last_access_time | DATETIME | Yes | false | NULL | NONE |
+------------------+-----------------+------+-------+---------+-------+
If you need to batch update the "balance" and "last access time" fields for the last 10 seconds, you can put the updates in a CSV file as follows:
1,500,2023-07-03 12:00:01
3,23,2023-07-03 12:00:02
18,9999999,2023-07-03 12:00:03
Then, add a header partial_columns:true and specify the relevant column names in the the Stream Load command:
curl --location-trusted -u root: -H "partial_columns:true" -H "column_separator:," -H "columns:id,balance,last_access_time" -T /tmp/test.csv http://127.0.0.1:48037/api/db1/user_profile/_stream_load
Farewell to OOM
Memory management might not be on the priority list of users until there is a memory problem. However, real-life analytics is full of extreme cases that are challenging memory stability. In large computation tasks, OOM errors often cause queries to fail or even result in a backend downtime.
To solve this, we have improved the memory data structures, reconstructed the MemTrackers, and introduced soft memory limits for queries and a GC mechansim to cope with process memory overflow. The new memory management mechanism allocates, caculates, and monitors memory more efficiently. According to benchmark tests, pressure tests, and user feedback, it eliminates most memory hotspots and backend downtime. Even if there is an OOM error, users can locate the question spot based on the logs and take actions accordingly.
In a word, Apache Doris 2.0 is able to handle complicated computation and large ETL/ELT operations with greater system stability.
Read more: https://doris.apache.org/blog/Memory_Management/
Support for Kubernetes Deployment
Older versions of Apache Doris communicate based on IP, so any host failure in Kubernetes deployment that causes a POD IP drift will lead to cluster unavailability. Now, version 2.0 supports FQDN. That means the failed Doris nodes can recover automatically without human intervention, which lays the foundation for Kubernetes deployment and elastic scaling.
Doc: https://doris.apache.org/docs/dev/install/k8s-deploy/
Support for Cross-Cluster Replication
For data synchronization across multiple clusters, Apache Doris used to require regular data backup and restoration via the Backup/Restore command. The process required intermediate storage and came with high latency. Apache Doris 2.0 Beta supports cross-cluster replication (CCR), which automates this process. Data changes at the database/table level in the source cluster will be synchronized to the target cluster. This feature allows for higher availability of data, read/write workload separation, and cross-data-center replication.
Behavior Change
- 1.2-lts can be scrolled and upgraded to 2.0-Beta, while 2.0-Alpha can be shut down and upgraded to 2.0-Beta
- Query optimizer switch default on
enable_ Nereids_ Planner=true; - Non vectorized code has been removed from the system, so 'enable' Vectorized The 'engine' parameter will no longer be effective;
- Add Parameter
enable_ Single_ Replica_ Compaction; - By default, use datev2, datetimev2, and decimalv3 to create tables, but do not support creating tables with datev1, datetimev1, and decimalv2;
- Decimalv3 is used by default in JDBC and Iceberg Catalog;
- Add AGG for date type_ State;
- Remove the cluster column from the backend table;
- For better compatibility with BI tools, when displaying create tables, display date v2 and date timev2 as date and date time.
- Added max in BE startup script_ Check for openfiles and swap, so if the system configuration is not reasonable, be may fail to start;
- Prohibit logging in without a password when accessing FE from localhost;
- When there is a Multi Catalog in the system, querying the information schema only displays data from the internal catalog by default;
- Limited the depth of the expression tree, defaulting to 200;
- The array string returns a single quotation mark to a double quotation mark;
- Rename Doris' process names to DorisFE and DorisBE;
Apache Doris 2.0 GA is just around the corner!
During the recent one and a half months after Apache Doris 2.0 Alpha was released, we have been honing the key features and perfectionating Doris according to the test feedback from our hundreds of enterprise users. Now, Apache Doris 2.0 Beta is more mature and stable, and will surely provide better user experience.
If you have any questions when investigating, testing, and deploying Apache Doris, please find us on Slack. Our developers will be happy to provide targeted support.
In addition to the foregoing functionality, some new features are undergoing the final debugging and will be available in Apache Doris 2.0 GA and the subsequent versions, including multi-table materialized view, expression support in single-table materialized view, dynamic schema table, and Doris binlog. We will keep you informed of our progress.
